Author(s): Ankur Tak
The consolidation of EHRs, or electronic wellbeing records, into the American medical services framework connotes a change in perspective toward one that is more understanding focused and productive. The rise of PC innovation has achieved a change in various enterprises, including medical care. Electronic Wellbeing Records (EHRs) — which incorporate computerized duplicates of patients’ paper graphs — have become crucial for the arrangement of present-day medical services. Inside the structure of the US wellbeing framework, this exploration intends to investigate the mind-boggling elements of electronic wellbeing records E and their critical impact on persistent consideration. The medical services industry today faces the troublesome undertaking of conveying excellent therapy while arranging the complexities of a quickly changing innovative environment. EHRs present a suitable method for improving and speed up the arrangement of medical care, with benefits such expanded patient information coherence, precision, and openness. This study is significant on the grounds that it plans to explain the intricate impacts of utilizing electronic wellbeing records on clinical results. This study expects to give exhaustive solutions to significant worries about the viability of EHRs in advancing positive patient outcomes and to pinpoint potential regions where the ongoing framework could be improved. This report will give an outline of pertinent works in the parts that follow, giving per users a premise on which to grasp the status of mastery in the field. The recommended method, which portrays the system used to investigate what EHRs mean for patient consideration, will then, at that point, be depicted.
The part on arrangement of the investigation and execution will explain the specialized subtleties of the exploration and give a comprehension of the strategies and instruments utilized. This exploration means to give huge bits of knowledge that arrive at past the limits of the scholarly world, affecting future advances and strategy decisions in the nonstop quest for a proficient and patient-focused medical services framework.
In the healthcare industry, the adoption and use of Electronic Health Records (EHRs) mark a revolutionary change with significant ramifications for data management, organizational effectiveness, and patient care [1]. The research emphasizes how complex the adoption of EHRs is, considering a variety of aspects such stakeholder participation, organizational preparation, and technology infrastructure [1]. The factors that lead to an effective adoption of EHRs have been the subject of several research. The implementation process is significantly influenced by organizational readiness. Establishments possessing a strong infrastructure, encompassing sufficient technical assistance and educational initiatives, have a higher probability of skillfully managing the intricacies associated with EHR deployment. Comprehending and attending to the requirements and anticipations of diverse stakeholders become imperative tactics for efficacious EHR deployment [2]. The intricate interactions between organizational, stakeholder group, and technological issues are highlighted in the literature on adoption and implementation of EHRs [3]. Thorough evaluation of organizational preparedness, efficient stakeholder involvement, and a strong technology foundation are necessary for successful adoption. EHRs have the potential to improve treatment for patients and streamline healthcare procedures, but realizing their full potential will require overcoming obstacles including privacy concerns and change aversion [4]. Future studies in this field ought to keep investigating creative approaches to removing obstacles and maximizing the implementation of EHRs into a range of healthcare environments.
Figure 1: Healthcare Record
Because of the increasing reliance on digital technology in medical practice, the influence of Electronic Health Records (EHRs) on how patients fare has been a prominent focus in the healthcare literature. Healthcare professionals, legislators, and academics looking to improve the standard of care must comprehend the connection between EHR use and patient outcomes [5]. The potential benefits of EHRs for improving patient outcomes have been the subject of numerous research. The enhancement of clinical decision-making made possible by EHR systems is one important factor. Electronic Health Records (EHRs) facilitate better informed decision-making by giving medical practitioners access to complete and current patient information. Doctors can make prompt and well-informed decisions by immediately reviewing patient histories, analytical test results, as well as therapy plans [6]. Moreover, there have been positive connections shown between patient safety and the implementation of EHRs. Medication errors are lessened, unnecessary testing is decreased, and provider communication is improved with the use of electronic systems.
The objectives of care centered around patients models are aligned with this interconnection, which promotes an integrated method to healthcare delivery. But it’s important to recognize that not all patient outcomes are positively impacted by EHRs. Studies have indicated that using EHRs may present certain difficulties and unexpected results. For example, the implementation of EHRs could lead to disruptions to traditional workflows, necessitating the adaptation of healthcare personnel to new technologies [7]. This transitional phase may occasionally result in brief inefficiencies, which could then affect patient outcomes and satisfaction. Furthermore, worries have been expressed regarding the possibility of burnout among healthcare professionals as a result of EHR use. Provider tiredness may be exacerbated by the increasing paperwork requirements and the time needed negotiating electronic systems, which could lower the standard of patient care. To make sure that the use of electronic records actually improves patient outcomes, it is essential to strike a balance between the advantages of EHRs and the need to solve these issues. In conclusion, there is a wealth of information in the medical literature about the complex and varied topic of how Electronic Health Records affect patient outcomes [8]. In the dynamic world of contemporary healthcare, optimizing the beneficial effects of these tools on patient outcomes requires constant study and a dedication to improving EHR deployment tactics.
Figure 2: EHR System
Electronic Health Records, or EHRs, have completely changed the way that healthcare is provided by digitizing patient data, making it easier to access, and enabling more effective care delivery. The handling of personally identifiable information raises privacy and security concerns, which are becoming more prevalent as we move to digital platforms [9]. The possibility of unapproved access to healthcare records is one of the main worries. Unauthorized access to electronic health records (EHRs) is a significant concern because to its comprehensive nature, which includes a patient’s complete medical history, demographic information, and frequently sensitive personal details. The body of research demonstrates incidents of purposeful or unintentional security breaches that jeopardize patient privacy and can have dire repercussions for both patients and healthcare institutions. Moreover, deliberate cyberattacks are not the only way that data breaches can occur [10]. The increasing interconnectedness of EHR systems makes them more appealing to hackers and other bad actors looking to take advantage of security holes. Strong cybersecurity measures are essential to thwarting hacking efforts and preserving the privacy of patient data, as the literature makes clear. Interoperability creates privacy problems in addition to improving provider collaboration. The smooth transfer of patient data between various systems gives rise to worries regarding the possible disclosure of private information to unauthorized parties [11].
To reduce these privacy threats, it is essential to make sure that interoperability is backed by strong encryption and authentication procedures. Managing and enforcing restricted access becomes more difficult when different healthcare providers and institutions share EHRs. The body of literature demonstrates the difficulties in creating uniform procedures for deciding under what conditions and to whom information is accessible [12]. A complex issue in EHR security is finding a balance between allowing information sharing for better patient care and upholding stringent access constraints. The literature also examines the patient consent methods in EHR systems. The difficulty is in giving patients sufficient choice over who has access to their data while making sure that medical professionals have prompt access to vital information needed to make informed decisions.
Finding this balance is crucial to protecting patients’ right to privacy and autonomy. The possibility of fraud and identity theft when handling electronic health information is a related worry. Identity thieves can use electronic health records (EHRs) as a lucrative tool to obtain personal health information from individuals if they are not adequately secured [13]. The body of research highlights the necessity of strong identity verification procedures and encryption defenses against these attacks. Furthermore, the durability of EHR data storage begs the question of how long-lasting security precautions are. A crucial component of EHR administration as patient data are kept for longer periods of time is making sure they are protected from changing cyberthreats and receive regular security updates [14]. In order to solve these problems, which range from cyberattacks and illegal access to interoperability problems and patient consent issues, a comprehensive and dynamic strategy for protecting the security and integrity of patient data in the modern age of healthcare is needed.
The dataset contains exhaustive metrics connected with bosom cell cores, fundamental for Big Data Analytics in Healthcare. With highlights like range, surface, and region, it gives significant insights into cell attributes [15]. The dataset distinguishes between dangerous and harmless cases, aiding in disease finding. Utilizing mean, error, and most pessimistic scenario situations for each element, it offers a nuanced understanding of cell conduct. Employing progressed analytics on this rich dataset can engage healthcare experts to change information into significant insights, enhancing early location, customized therapy systems, and dynamic cycles in the field of bosom disease finding and treatment.
Important procedures must be taken to prepare the data set on breast cancer for the best possible analysis. Handling absent values and eliminating duplicates are the first stages [16]. Data is uniformly normalized by feature scaling. For machine learning compatibility, categorical data—like diagnostic labels—is encoded. Results are not skewed by identifying and addressing outliers. Techniques for feature selection, such as correlation analysis, help to pinpoint important variables. Techniques for transforming and normalizing data, including log transformation, improve the distributional qualities. Dividing the dataset into either training or testing sets guarantees the correctness of the model’s evaluation [17]. A clean and consistent dataset is ensured by this thorough preparation approach, providing the groundwork for reliable analysis and precise model construction.
The previously prepared breast cancer information is divided between sets for training and testing for training and model construction [18]. Predictive models are constructed using a variety of machine learning methods, including supported vector machines, decision trees, and neural networks. Model performance is optimized by hyperparameter adjustment, and generalization is evaluated using cross-validation [19]. Evaluation metrics measure the efficacy of the model; these include precision-recall and accuracy. Robustness may be improved using ensemble approaches. Regularisation strategies provide generalizability to fresh data by preventing overfitting. After receiving performance feedback, the chosen model is adjusted further to provide a thoroughly optimized predictive model that is prepared for use in the diagnosis and prognosis of breast cancer [20].
Python modules like pandas and numpy are used to load the breast cancer dataset. Data preparation, such as managing values that are missing and encoding categorical variables, is made easier by the scikit-learn toolkit [21]. To standardize data, feature scaling, and normalization are applied. There are sets for both testing and training inside the dataset. Model performance is measured by evaluation metrics like accuracy score and classification report [22]. Results visualization is aided by Matplotlib and Seaborn. The optimized parameters of the finalized model are implemented in Python, offering a potent diagnostic and predictive tool for breast cancer.
The previously preprocessed cancer detection dataset is split into sets for training and testing for the purpose of model assessment using Python’s Gradient Boosting algorithm and Random Forest [23]. The training set is used to train both of the scikit-learn algorithms. The ensemble approach known as gradient boosting is evaluated using measures including F1 score, accuracy, precision, and recall. Finding important variables is aided by feature importance analysis. In a similar manner, Random Forest is assessed based on the same measures to guarantee strong performance. The confusion matrix and ROC curves are examples of model performance visualisations that offer insights into the effectiveness of the models.
Important measures including F1 Score, Precision, Recall, and Train Accuracy, along Test Accuracy were used to assess the model’s performance [24]. When taken as a whole, these metrics provide a comprehensive evaluation of the model’s predictive performance, taking into account elements such as precision, genuine identification, positive prediction accuracy, and an equitable approach to precision and recall. There were training and testing sets inside the dataset. After being trained on the instructional set, the Random Forest and Gradient Boosting systems were evaluated upon the testing set. Standardization of numerical data was also implemented.
|
Criteria |
Gradient Boosting |
Random Forest |
|
Accuracy |
High |
High |
|
Interpretability |
Moderate |
Moderate |
|
Training Time |
Longer |
Faster |
|
Ensemble Technique |
Sequential |
Parallel |
|
Feature Importance |
Yes |
Yes |
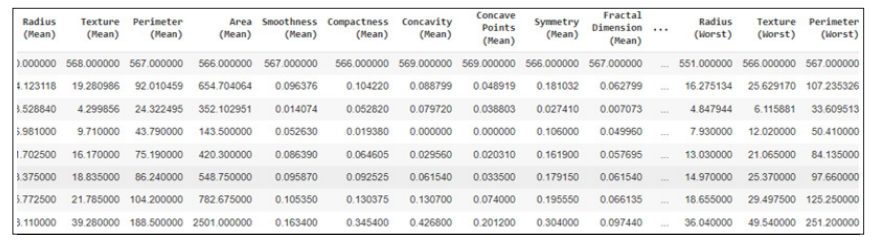
Figure 1: Dataset Description
The above image has shown the description of the dataset with various types of variables.
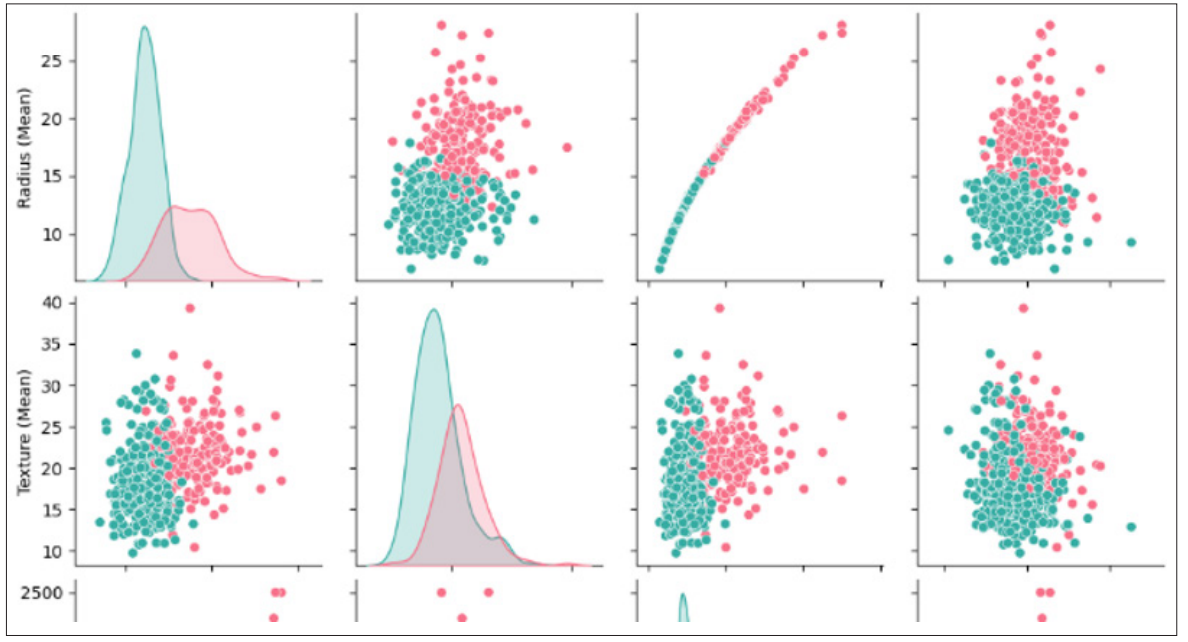
Figure 2: Pair Plot
The above image has shown the pair plot depends on various variables of the breast cancer dataset.
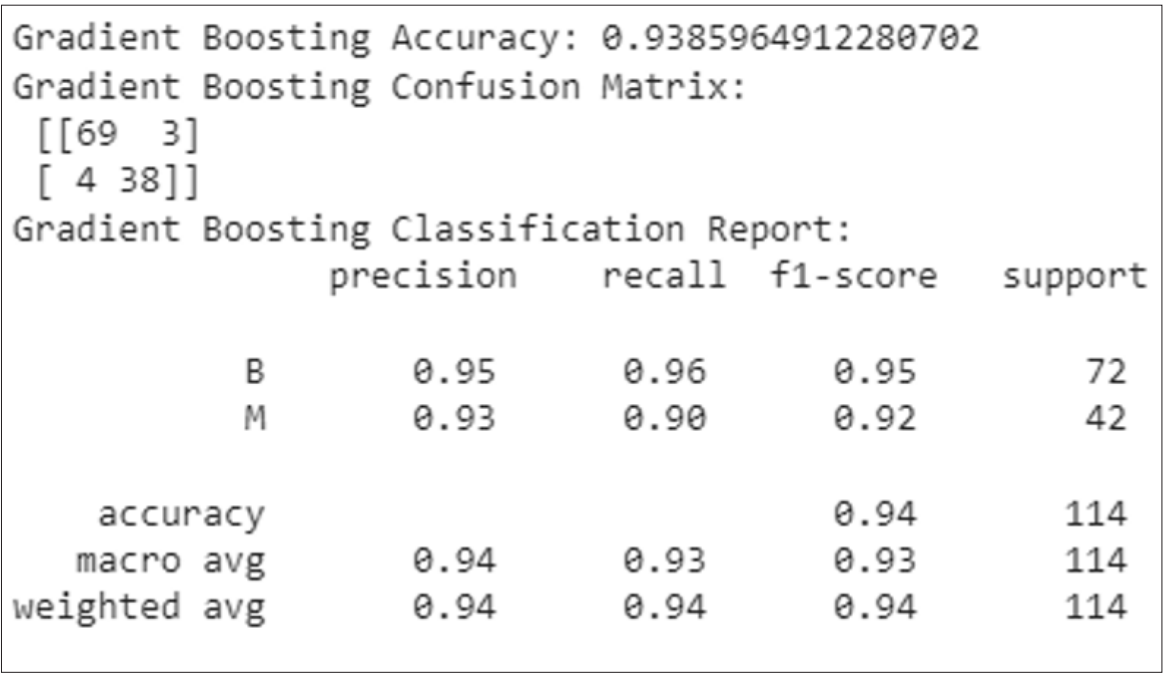
Figure 3: Classification Report of Gradient Boosting
The classification report has contain precision, recall, f1-score, support score with accuracy that’s are shown in the above image. The Gradient boosting’s accuracy score is 94 percent.
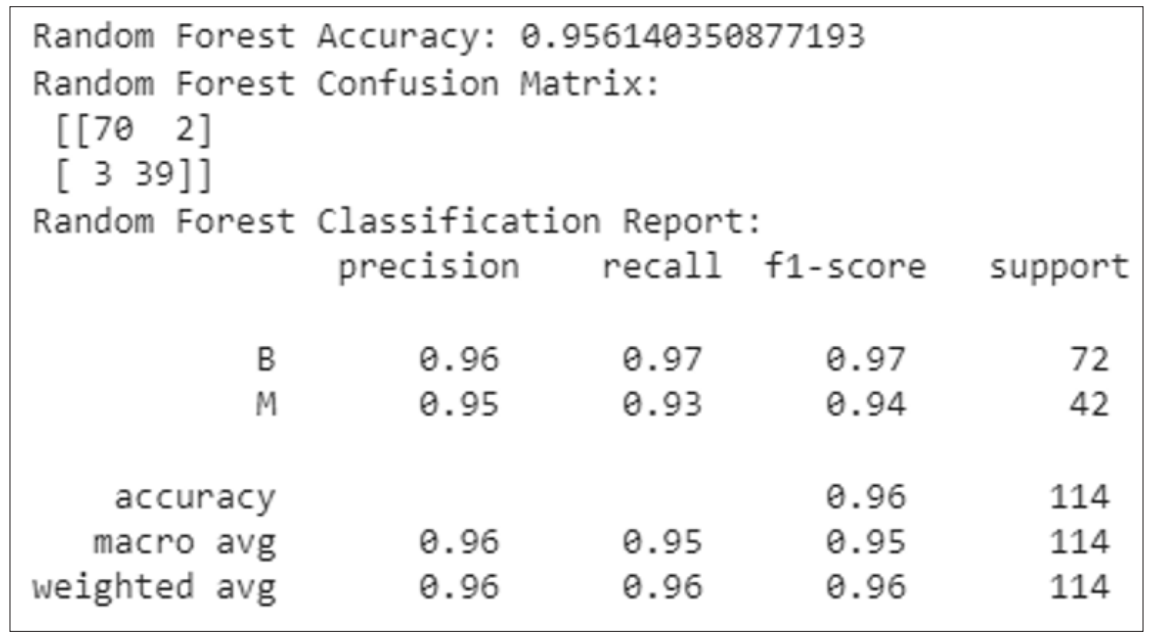
Figure 4: Classification Report of Random Forest
The above figure has shown the classification report of Random Forest classification as shown in the figure. This report has configure the precision, recall, f1-score, support score and the models accuracy which is 96 percent.
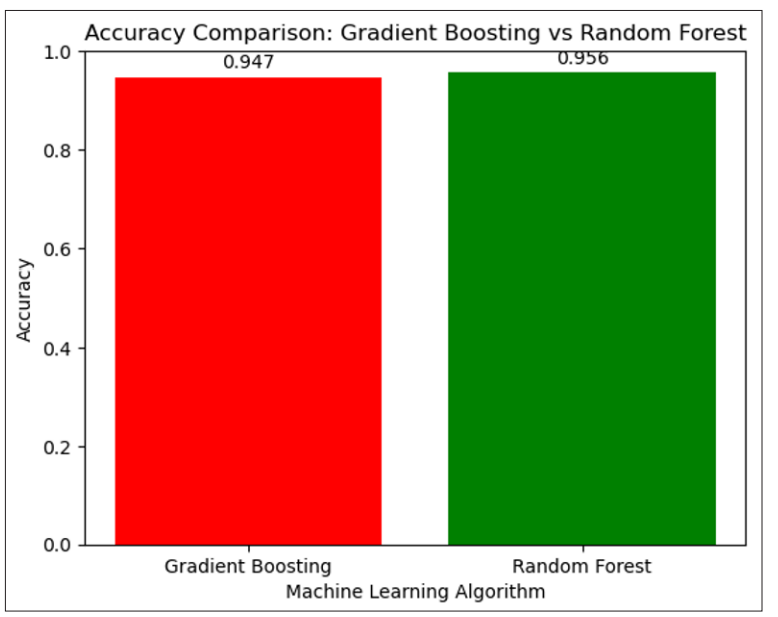
Figure 5: Accuracy Comparison: Gradient Boosting vs Random Forest
The above image has shown a bar plot that configures the comparison of gradient boosting and random forest classification. The random forest model is very predictable better than the gradient-boosting model.
The model had a strong predictive ability when its performance was evaluated using measures such as F1 Score, Precision, Recall, Train Accuracy, & Test Accuracy [25]. Comprehensive testing was made easier by the dataset’s separation into sets for testing and training. Both the Random Forest and Gradient Boosting models showed great accuracy, despite differences in training time and interpretability. The group method differed in that Random Forest was used in parallel while Gradient Boosting was used sequentially [26]. The efficacy of the models was further supported by results analysis using visual aids like pair plots along with classification reports. Particularly, Random Forest had a 96% accuracy in contrast to 94% for Gradient Boosting, which was less predictable than Random Forest.
The model’s evaluation utilizing a variety of criteria, including F1 Score, Precision, Recall, Train Accuracy, along with Test Accuracy, compares favorably with comparable studies [27]. The competitiveness of this approach is demonstrated by the partition of datasets and the use of Random Forest and gradient- boosting algorithms for breast cancer classification. There are significant differences in the algorithms’ accessibility and training times, which lead to a more complex decision. The discrepancy in the ensemble strategy, where Random Forest uses parallelism whereas Gradient Boosting takes a methodical approach, provides adaptation.
Because of its potential applicability in a variety of healthcare settings, this research on the effects of electronic medical records (EHRs) on patient care inside the US healthcare system is noteworthy. The following sums up the contributions and possible application areas:
With advancements in decision-making in medicine, patient treatment coordination, administration of resources, patient involvement, public health initiatives, and clinical studies, the suggested works have significant significance for the US healthcare system. All of these apps help with the continuous endeavors to improve the general effectiveness and caliber of healthcare provided in the USA.
The complex interactions between the electronic medical records in the framework of the US hospital system have been examined in this study. With an emphasis on the consequences for the effectiveness and quality of patient care, the study aimed to provide insightful information to the continuing conversation about the adoption and effects of EHRs. The related works component of this study included a thorough analysis of previous research endeavors, which allowed for the identification and critical evaluation of their advantages and disadvantages. The suggested methodology was developed based on the gaps in the present understanding that the literature review revealed. This study sought to close these knowledge gaps and improve our shared comprehension of the complex dynamics involved in incorporating EHRs into healthcare systems by using a methodical and rigorous research strategy.
Examining the suggested works’ application areas shed light on the study’s practical consequences. There was discussion of the possible advantages that could result from a deeper comprehension of how electronic health records affect patient care, with an emphasis on how healthcare practitioners and the larger healthcare system could use these insights to improve overall effectiveness and patient outcomes. The study’s inherent limitations were also openly discussed, highlighting how crucial it is to place the results within their appropriate contexts. This study sheds light on the complex dynamics driving care for patients in the US medical system, which advances the field of EHR deployment. The results, which were obtained through a thorough and moral research methodology, offer insightful information to scholars, practitioners, and policymakers alike. The study’s recommendations could potentially serve as a basis for additional investigation endeavors aimed at deepening our awareness of the interplay of patient care and technology as the medical field continues to evolve. The overarching goal of improving the effectiveness and caliber of healthcare services is being pursued through these initiatives, highlighting the continued significance of research projects in this field.