Author(s): Girish Ganachari
This study discusses synthetic data synthesis for real-time data pipeline enhancements. Many companies can scale, cost-effectively, and privately train and test machine learning models using synthetic data. Key applications include advanced simulations, model effectiveness, and privacy. Despite data realism, computational complexity, and domain-specific requirements, generative models and integration approaches are promising. Legal and ethical issues must be resolved for acceptance. This study proves synthetic data's effectiveness, dependability, and regulatory compliance, revolutionising data-driven systems.
Big data has altered many organisations, needing complicated data-driven systems to assess enormous data sets. Data pipelines that are able to function in real time are required in order to adequately meet the requirements of this demand. Companies can swiftly examine data via continuous data flow pipes. This facilitates quick, informed decisions. Avoid delays in financial trading, healthcare monitoring, and autonomous driving using real-time data pipelines. Creating realistic datasets for testing and training real-time data pipelines is tough despite its importance. Data privacy issues. Medical information and financial data are difficult to use for training due to privacy regulations. Specialised fields with costly or complex data collecting may have little data. Training unsuitable models without real-world data may cause biases and system performance issues. These issues may be resolved using synthetic data. Synthetic data resembles actual data. Advanced algorithms and models may simulate several data situations to create adaptable, scalable synthetic data. It anonymises sensitive data and provides huge, diverse datasets for testing and training. Synthetic data builds and optimises real- time pipelines. Synthetic data may help companies meet privacy rules, generate data-driven apps, and bypass data constraints. In data-driven systems, synthetic data production for real-time data pipelines has many uses, benefits, problems, and future prospects.

Figure: 1. DART framework overview
Training datasets for machine learning algorithms may be improved by the creation of false data. Synthetic data may generate enormous volumes of training data cheaply. Planche et al. enhanced 2.5D recognition algorithms using CAD model synthetic data. This strategy provides a wide range of training samples for model performance while reducing data collection and annotation costs [1].
Figure 2: An example DNN
Model with one input layer, several hidden layers, and one output layer Compositing synthetic data by Tripathi et al. improved computer vision model dependability and effectiveness. Synthetic data provides diverse, well-annotated training situations to increase model generalisation. This improves real-world projections [2]. Researchers may use synthetic data tailored to their purposes to conduct experiments in difficult-to-replicate situations. Improves machine learning model efficiency.
In sensitive sectors like banking and healthcare, real-time data privacy is essential. Synthetic data can tackle these problems by balancing privacy and utility. Synthetic data may preserve statistical traits without identifying information, according to El Emam, Mosquera, and Hoptroff [3]. This preserves user privacy when training and assessing bogus datasets. Synthetic data may also fulfil GDPR privacy requirements. Creating data without identifying individuals lets companies send and analyse information without infringing privacy rules. Cross-institutional studies and collaborative research benefit from this when data interchange is important but privacy considerations prohibit it.
Simulating and testing real-time data pipelines needs synthetic data. Studying monocular depth estimation. In controlled experiments, Atapour-Abarghouei and Breckon tested depth estimate algorithms using fake data. Researchers may test algorithms in synthetic settings to simulate dangerous or challenging conditions that are hard to replicate [4]. Before deployment, this function calibrates systems to reduce errors and increase reliability. To evaluate algorithm reliability and flexibility, autonomous automobiles may travel in simulated fog or clear sky. Medical items may be tested under different physiological settings using synthetic patient data.

Figure 3: Comparison of object detection results using SSD
Domain shift issue solving is a key application of synthetic data. Domain shift separates a model's training and real-world data. It generally reduces model performance. Customising synthetic data may narrow this gap and make models more lifelike. Sankaranarayanan et al. addressed semantic segmentation domain shift using synthetic data. Researchers created phoney datasets that resembled the desired domain to increase model performance. It's beneficial when acquiring tagged data from the target location is hard or impossible. Synthetic data may simulate illumination, meteorological, and other environmental factors to assess model reliability and performance.

Figure 4: Examples of data generated, simulating a multi-shot depth sensor
Synthetic data outperforms real-world data in scalability and variety. Nikolenko advocated generating huge datasets for individual requirements to ensure systems can handle different data inputs and scenarios. [5]. Real-time data pipeline generation and assessment across industries need flexibility. Synthetic data synthesis is cheaper than real-world data collection and analysis. According to Tsirikoglou et al. [6], procedural modelling and physically based rendering save money in automotive applications. Synthetic data production cuts data preparation expenses by eliminating fieldwork and annotating. Synthetic data's scalability, adaptability, and affordability make it appealing for automotive and healthcare applications.
Improved Model Performance and Complex Simulations Synthetic data may assist machine learning models by providing well-labeled training datasets. Wood et al. proved that high- quality synthetic data trains robust models like real-world data. They acquired cutting-edge facial analysis results from produced data [7]. Real-time data pipelines need accuracy and reliability, therefore model performance must improve. Synthetic data may also imitate complicated situations that are hard to replicate with real data. Wang et al. showed that synthetic data can train blind super-resolution models for real-world conditions, making training challenging [8]. Several real-time applications need unexpected event prediction. Synthetic instances may assist models handle unusual classes and conditions, enhancing generalisation, Beery et al. found [25]. Synthetic data enhances real-time data pipelines and application performance.
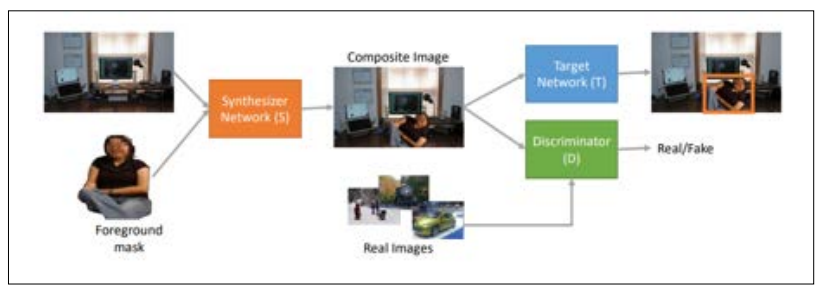
Figure 5: Our pipeline consists of three components: a synthesizer S, the target network T, and a natural image discriminator
Similarity to genuine data is prioritised in synthetic data development. High-order degradation algorithms may replicate realistic degradations, although ultimate realism is challenging because synthetic data may vary from actual data [8]. Synthetic data lacks realism, which may impair real-time data pipeline training and assessment. Quality synthetic data demands plenty of computing power. Domain adaptation may limit large-scale systems due to computationally demanding end-to-end synthetic data production [9]. To overcome computational challenges and make synthetic data creation viable and relevant, efficient methods and scalable infrastructure are required.
Domain-Specific Requirements and Integration with Real Data The demands of each area differ, hence synthetic data must be customised. Developers need domain-specific synthetic datasets to verify appropriateness. This method requires specific instruments and subject area knowledge, making it challenging and time- consuming [10]. Healthcare synthetic data must accurately reflect medical issues, whereas autonomous automobile data must simulate various driving conditions. Integrating synthetic and real data is challenging for bias adjustment and consistency. The semantic dense fog scene interpretation model adaptation employs synthetic and real data, showing the difficulty of data integration [23]. In real-time data pipelines, synthetic data must match actual data without interrupting it for reliable results. These issues must be addressed to use synthetic data across applications without unintended repercussions.
In order to produce synthetic data, VAEs and GANs are absolutely necessary [3]. High-quality synthetic data showed promise from these models. Further study will enhance their real-time data stream. Real-time systems require artificial data generation to generate data quickly and increase data pipeline flexibility [5,7]. Transparency, justice, and accountability in synthetic data usage establish trust. Ethics and regulation are needed [3,12]. Enhancing synthetic data with additional scenarios enhances model generalisation and durability [16]. Wrap 20 in square brackets. Real-time synthetic data adjustment techniques are needed to accurately represent real-world occurrences in dynamic data adaption in real-time systems [21]. Setting clear norms and criteria for synthetic data generation and use would help address challenges and assure its ethical and successful use across several fields.

Figure 6: Using a discriminator improves the realism of generated images.
Many sectors employ synthetic data, demonstrating its adaptability. To create synthetic data, Tsirikoglou et al. researched procedural modelling and physically based rendering in cars. The study projected autonomous vehicle training and testing driving and environmental conditions [6]. Synthetic patient data lets healthcare companies securely share and analyse medical data. The technique improves data privacy and availability [3]. Agriculture benefits from semantic segmentation data synthesis. These technologies improved precision farming by creating new agricultural settings. This helps crop monitoring model training and disease detection [24]. Urban planning misrepresents population and transit demand to predict urban dynamics and justify infrastructure [22]. Natural language processing adapts question-answering systems to new areas using synthetic data. Large training datasets help models [9]. Environmental monitoring, especially severe weather modelling, uses synthetic data. Replicating densely crowded and foggy situations improves monitoring and navigation [15,23]. These case studies demonstrate synthetic data's benefits across industries.
Synthetic data is private, scalable, and cost-effective for real- time pipelines. Using this technique, enormous databases with diverse data may be created and changed. This trains and analyses industry-wide machine learning models. GANs, VAEs, and enhanced integration methods offer a bright future for synthetic data production despite data realism, computing complexity, and domain-specific needs. By creating these technologies, synthetic data can match real-world data and decrease disparities. Synthetic data confidence, accountability, equality, and transparency need ethical and legal resolution. Synthetic data production and usage must be managed for ethical and legal reasons. In current data- driven systems, synthetic data may increase real-time data pipeline efficiency, reliability, and flexibility. Companies may utilise data- driven insights legally and privately. Innovation and advancement in many fields will ensue.