Author(s): Ahmed Ali Dawud* and Getamesay Haile
A crucial aspect of pneumonic pathology is attributed and analyzed by respiratory sound, which also provides information on the patient's lung symptoms.Almost all health institutions worldwide acquire pneumonia as a common and therapeutically challenging diagnosis that can lead to a severe body response to an infection, critical illness, and respiratory failure. It is well acknowledged that clinical diagnosis and prognosis are insufficient for the proper assessment of the severity of the disease due to the complexity of its pathogenesis. Auscultation and chest X-ray (CXR) images are currently the primary methods for identifying and diagnosing pneumonia, but it can be difficult for a trained radiologist to identify pneumonia from a CXR image or for a pathologist to do so using a stethoscope because accurate interpretation of respiratory sounds requires significant clinical expertise.
We attempted to create an automated classification of respiratory sounds to detect pneumonia as well as a more complicated classification to distinguish between different forms of pathology by using a deep learning convolutional neural network to classify the six classes (healthy, COPD, URTI, bronchiectasis, pneumonia, and bronchiolitis) of sounds recorded in a clinical setting. In the proposed method for pneumonia detection and pathological respiratory sound classification, a pertained picture feature extractor of series, respiratory sound, and CNN classifier are all used. The CNN model had an average precision of 98.8%, with a split among the classes of 97.80%, 87.60%, 95.0%, 85%, 100%, and 100% for COPD, healthy, URTI, bronchiectasis, pneumonia, and bronchiolitis, respectively. It detected abnormal sounds with an accuracy of 94.2% and pneumonia with an accuracy of 100%. The performance results obtained suggest that CNN is a viable tool for detecting specific characteristics in respiratory data and is capable of accurately classifying pneumonia.
When air flows during the process of breathing, lung sound is created, which refers to all respiratory sounds heard or recognized across the chest wall or within the chest [1]. Lung auscultation is used in clinical practice to identify pulmonary disorders, while respiratory sounds are the basic element of pneumonic pathologies, such as COVID-19, and pneumonia and offer symptomatic data about a patient's lung. Lung auscultation is the process of listening to a patient's lung sounds using a stethoscope to rule out serious illnesses and identify various pulmonary problems. As a result, for centuries, a stethoscope has been essential medical equipment for physicians to use in diagnosing lung problems. However, recognizing the refined distinctions among different lung sounds requires sufficient training and clinical experience. As COVID-19 sweeps the globe, lung auscultation remains vital for monitoring confirmed cases [2].
Remote automated auscultation methods may be essential in reducing infection risks among medical staff. As a result, artificial intelligence may be used to support clinicians in doing remote and accurate auscultation, which is becoming increasingly important. Recent research has established a number of lung sound categories. Lung sounds may be divided into two types: normal and abnormal [3]. Normal noise can be heard from the beginning of the inhalation phase to the beginning of the exhalation phase. The spectral properties of these normal sounds demonstrate that they have peaked with typical frequencies below 100 Hz, and the sound energy drops abruptly between 100 and 200 Hz [4]. Pathological sounds are sounds superimposed on normal a sound which is generated by respiratory disorder.
Furthermore, respiratory sounds are divided into two types: continuous and discontinuous. Wheeze and crackle were terms used to describe continuous and discontinuous noises, respectively. The word continuous denotes that the noises last for more than 250 milliseconds [5]. Narrowing of the airway diameter causes continuous noise [6]. The pitches of these continuous sounds are determined by two things. The bulk and suppleness of the airway walls are one factor, while the velocity of airflow is another [7]. The pitches of the continuous sounds match the power spectrum's prominent frequencies. Continuous adventitious sounds can clinically signify obstructive airway diseases such as asthma and chronic obstructive pulmonary disease (COPD) [8].
Discontinuous sounds (crackles) are nonmusical, brief, explosive sounds that typically last less than 20 milliseconds [9]. The sudden opening or closure of the airways, which are abnormally closed due to the lung's high elastic recoil pressure, causes those discontinuous noises. Depending on the airway diameter, the frequency of discontinuous noises ranges from 100 to 2000 Hz [10]. Furthermore, in individuals with pneumonia and interstitial lung illnesses, discontinuous sounds can be linked to disease progression and severity [9, 10].
This paper aims to propose signal analysis in conjunction with machine learning approaches that can provide better results in pneumonia detection for better health care services. Feature engineering of machine learning algorithms can be a useful way to differentiate between the same adventitious sounds of different pulmonic diseases. Thus, there is a need for an efficient, economic, convenient, and noninvasive diagnostic methodology for the identification of pulmonic disease.
In recent years, many researchers have been working on the automatic classification of respiratory sounds by using different deep learning models. Using a deep learning model enhances the accuracy of respiratory sound classification. In this section, we review previous attempts made on respiratory sound classification models using deep learning which helps us to understand the basic features of pneumonia and other respiratory sounds.
In the author suggests using deep learning to classify crackles, wheezes, and rhonchi as respiratory sounds in the clinical setting [11]. A total of 1918 respiratory sounds captured in a clinical context were divided into categories by the author using deep learning convolutional neural networks (CNNs). They combined a pretrained image feature extractor of series, respiratory sound, and a CNN classifier to create their prediction model for respiratory sound classification. The authors conclude that their study provides good classification accuracy for respiratory sounds, but that pneumonia is not taken into account.
The author proposed combining CNN and LSTM to identify pulmonary diseases from lung sounds [12]. They made use of 103 patient datasets from locally recorded lung sounds using stethoscope from King Abdullah University Hospital, Jordan University of Science and Technology. They used bidirectional short-term memory units and convolutional neural networks as the two stages of their network design. They used Cohen's kappa, accuracy, sensitivity, specificity, precision, and F1-score as performance assessment measures, and their model was assessed using a k-fold cross-validation procedure of 10-fold. Their CNN + BDLSTM model classified patients according to lung illness with an average accuracy of 99.62% and a precision of 98.85%.
The authors proposed classifying lung sounds using CNN models that are depthwise separable and combine STFT and MFCC characteristics [13]. For the reduced DS-CNN (depthwise separable convolution neural network) model, the authors selected a total of three features: the short-time Fourier transformed (STFT), the Mel-frequency cepstral coefficient (MFCC) and the fused features of the two. The accuracy of DS-CNN models trained on either the two types of feature, according to the ir experiment, was 82.27% and 73.02%, respectively, and when both features were employed, it was 85.74%. Proposed using a convolutional neural network to classify respiration sounds [14]. To accomplish this, they created a visual representation of each audio sample employing the same techniques used to classify images with high precision, and they extracted resources with Mel Frequency Cepstral Coefficients (MFCCs) for respiratory disease classification.
From the related works, we noted that applying a deep learning model will enhance the performance of respiratory sound classification. Therefore, this research proposes to develop deep learning-based respiratory sound classification that can enhance the accuracy of existing respiratory sound classification models and pneumonia detection for better diagnosis of pneumonia.
This study's proposed approach for detecting pneumonia based on respiratory sound classification into predetermined classes consists of four steps. Figure 1 demonstrates signal acquisition, preprocessing, model development, and model evaluation.
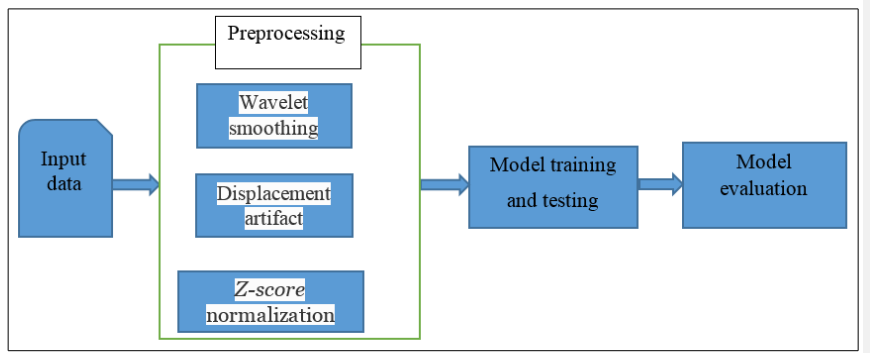
Figure 1: Proposed Methodologies for the Detection of Pneumonia
The 920 recordings that were obtained from 126 subjects made up the International Conference on Biomedical and Health Informatics (ICBHI) dataset, which was produced by two research teams (Greece and Portugal) [15]. A total of 5.5 hours of sound and 6898 breathing cycles were captured. To create a difficult dataset, high noise levels were used to mimic real-world conditions. In this study, respiratory sounds were taken from healthy subjects, people with chronic obstructive pulmonary disease (COPD), people with upper respiratory tract infections (URTI), people with pneumonia, and people with bronchiolitis.
Lung sound recordings are vulnerable to acoustic disturbance from
ambient noise, background conversation, electronic interference,
or any stethoscope displacement, similar to any other biological
signal that is electronically recorded [16]. Therefore, it is crucial
to ensure the signals are treated and smoothed before any feature
extraction steps are taken. The current study followed a number
of preprocessing processes, including [12]:
•1D wavelet smoothing
• Displacement artifact removal
• z-score normalization
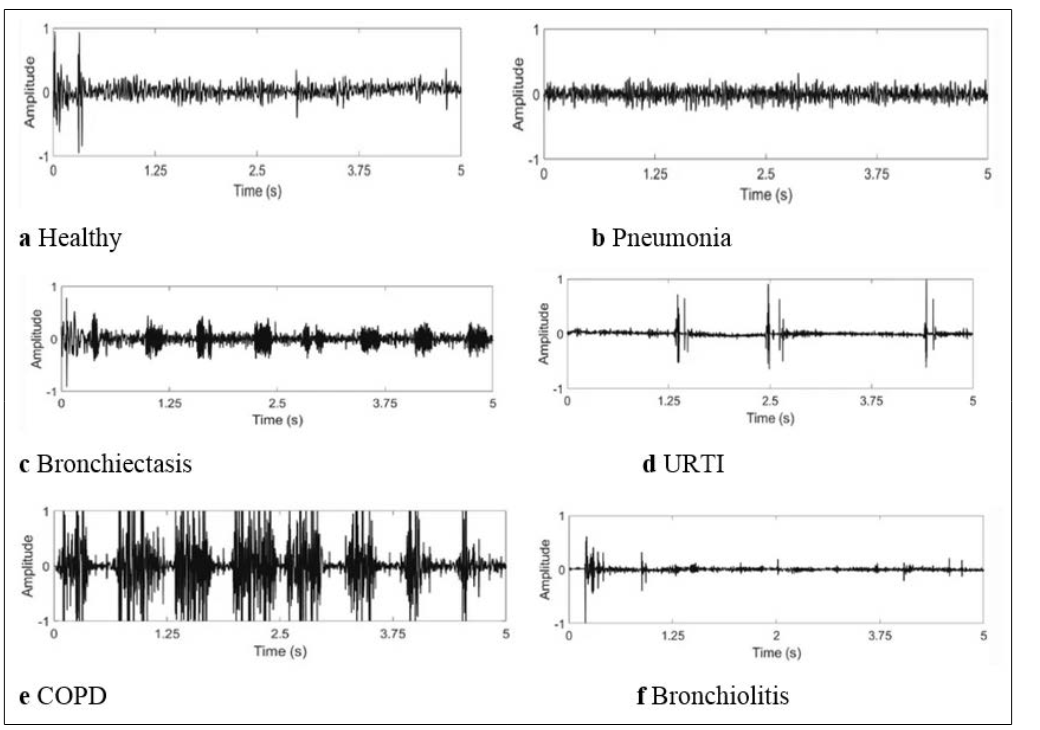
Figure 2: Examples of lung sound signals from healthy individuals and patients with five types of respiratory diseases: a healthy, b pneumonia, c bronchiectasis, d URTI, e COPD and f bronchiolitis

characteristics about the signal's entire spatial dimensionality may be extracted. In contrast, LSTM collects the characteristics following changes in the temporal domain. Better results are often obtained when building a model to predict signals based on their spatial and temporal features by integrating the two networks [22]. Additionally, the model's effectiveness was assessed for both the merged network and while running independently as CNN.
Several indicators were incorporated in this work to investigate the classification confusion matrix and evaluate the performance of the proposed model. After tenfold cross-validation of the training/ classification method, the confusion matrix was constructed sequentially after each fold, and all evaluation metrics were derived from the total confusion matrix. These metrics are given by:

Figure 3 only shows the preprocessing results for the 2.5 s segment for visual purposes. Figure 4 illustrates the outcomes of the metrics used to assess how well the neural network model performed. As illustrated in part, the proposed method successfully eliminates any noise artifacts caused by nearby noise sources and extremely low frequencies while keeping any displacement or movement artifacts (b). After the signal's z score was normalized prior to the detection of pneumonia, the final signal utilized for training and classification is displayed in section (d).
MATLAB software R2019 a was used to implement the proposed method. The experiments were run on an Intel Core i7 computer with 32 GB of RAM. A 4 GB GPU and 8 GB display memory processing unit were used for the training procedure (VRAM). The entire training/classification scheme took approximately 15 minutes to complete because each fold was taught for 2 minutes. Under the aforementioned machine parameters for the detection of pneumonia and other respiratory illness classes, the prediction of the per-patient class took less than a second. Figure 4 shows a tenfold confusion matrix of the original vs predicted disorders for the CNN to evaluate its performance.
The CNN model has the highest average precision in the classification process, with a 98.85% split among the classes of 97.80%, 57.60%, 50.0%, 75%, 100%, and 100% for COPD, healthy, URTI, bronchiectasis, pneumonia, and bronchiolitis, respectively.
In comparison to previous models, the proposed approach exhibited the best levels of pneumonia prediction accuracy. The fact that each study used a different number of recordings to classify a different number of groups based on respiratory sounds is important to note. However, because pneumonia has a significant impact on many aspects of respiratory illness, our study primarily focused on distinguishing it from other respiratory problems.
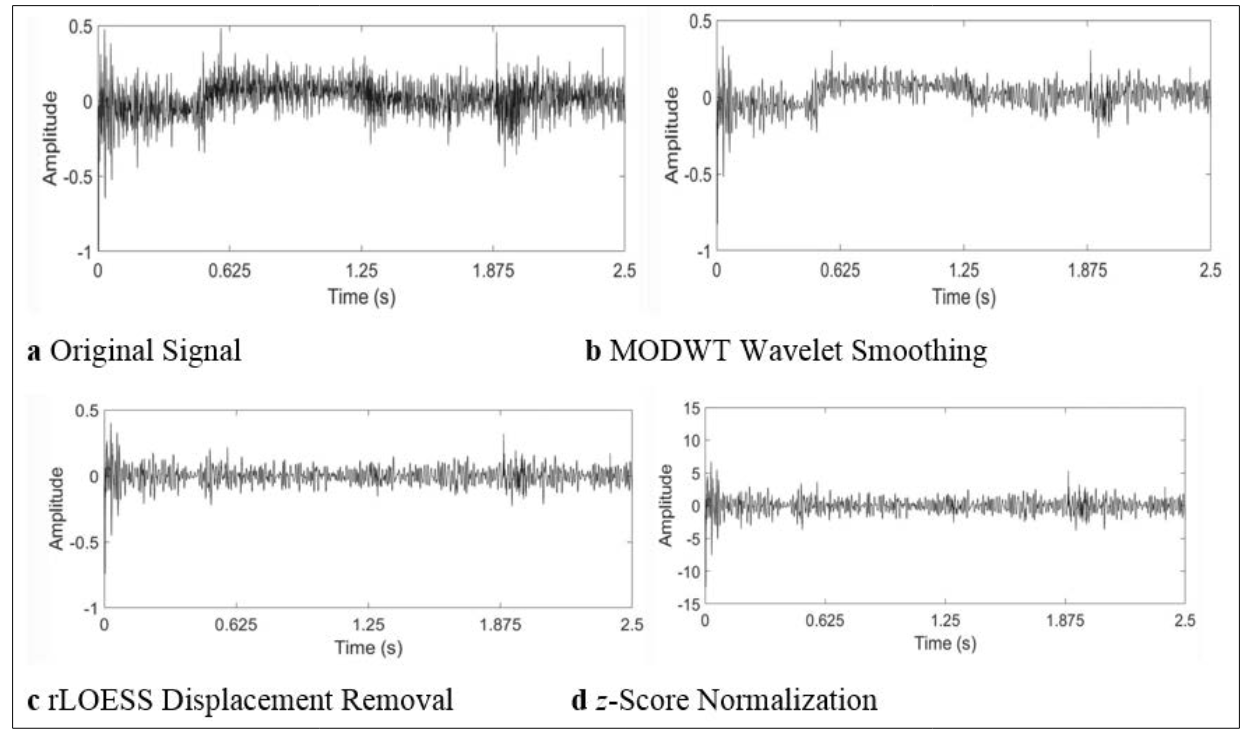
Figure 3: Preprocessing of a sample lung sound signal (2.5 s segment): a Original Signal, b MODWT Wavelet Smoothing, c rLOESS Displacement Removal, d z Score Normalization
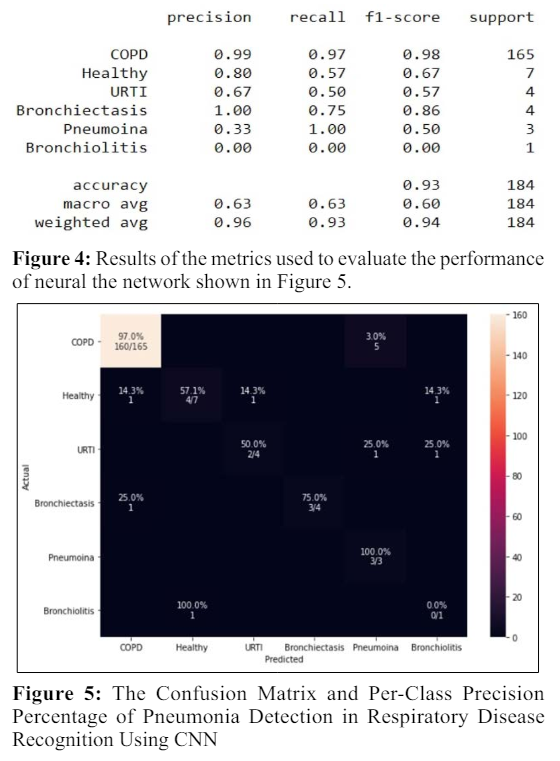
Figure 5 demonstrates the confusion matrices of the experiment test. With this, it is possible to show that the implementation had the best performance for the detection of pneumonia based on respiratory sound classification, as well as to analyze the training history for tests in Figures 6 and 7. The curves of training accuracy and validation accuracy, training loss and validation loss for the experiment are presented in Figures 6 and 7, while the confusion matrices that give the number of detected signals in the test are shown in Figure 5.
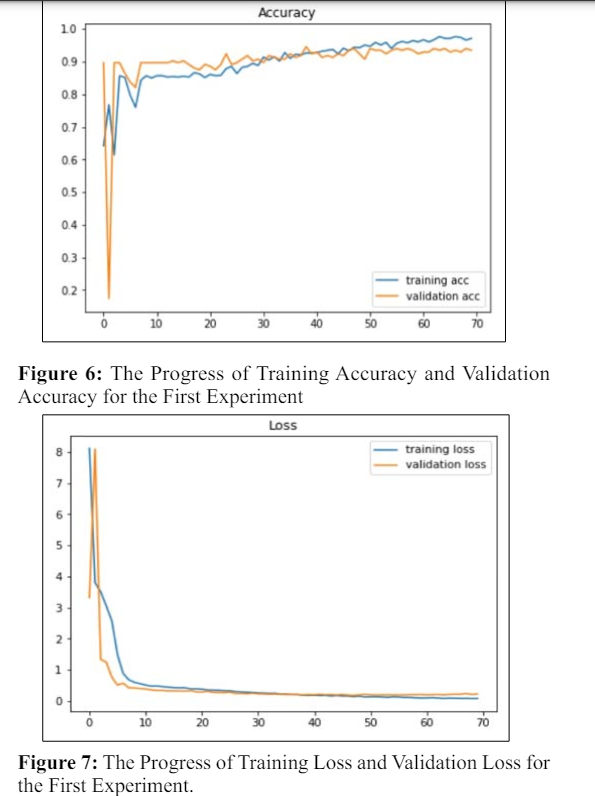
Figures 6 and 7 demonstrate that the experiment's training accuracy performs better than its validation accuracy. This indicates that the model can be trained more effectively using the distribution of classes in the training. The method proposed in this article gives results above 94% in the classification of respiratory sounds using six classes and 100% for the detection of pneumonia among respiratory diseases available in the database used.
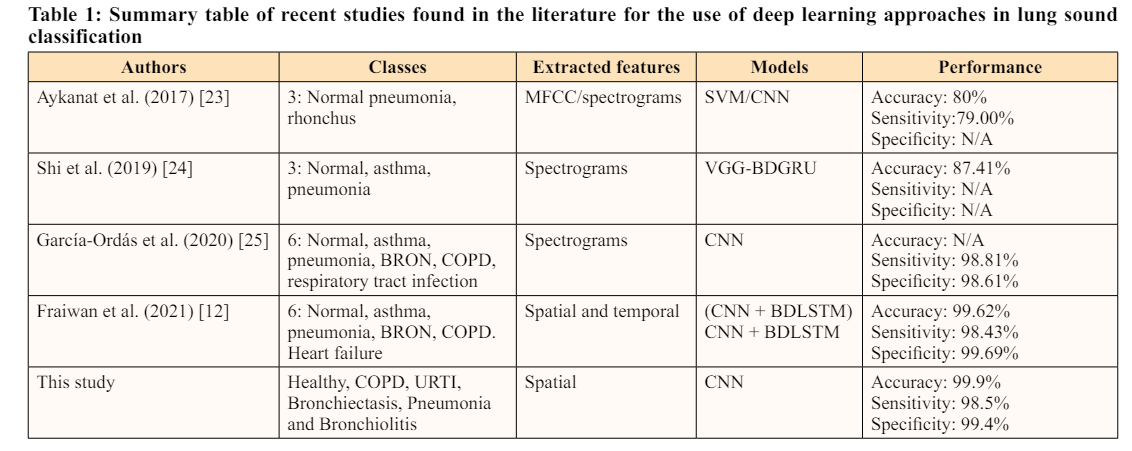
According to Table 1's results, it is obvious that the given method had higher classification accuracy than the studies that were examined, which might result in a more accurate diagnosis of pneumonia. The created algorithm can therefore identify pneumonia and classify the five types of respiratory sound signals completely automatically and with sufficient reliability.
Based on the research methodology, a convolutional neural network with a deep learning framework was created that initially integrates MATLAB software R2019a and processing algorithms such as 1D wavelet smoothing, displacement artifact removal, and z-score normalization for improved respiratory sound classification and pneumonia detection. This algorithm has an overall average accuracy of 94.2% for classifying respiratory sounds into various respiratory disorders, with 100% accuracy for predicting pneumonia. This study significantly improved the results of using a deep learning-trained model in clinical settings to help doctors make decisions on the diagnosis of pneumonia.
The performance results obtained suggest that CNN is a viable tool for detecting specific characteristics in respiratory data and is capable of accurately classifying pneumonia inside and outside of laboratory environments, which inspires and enables further research in the analysis of respiratory sounds. However, the classification for other respiratory diseases may be further improved by modifying both the preprocessing techniques and the training structure without affecting the performance of pneumonia detection. Future research will thus focus on extending the dataset's size to include more subjects and a wider spectrum of pathologies, such as COVID-19, to increase the proposed model's reliability