Author(s): Arjun Mantri
The process of transferring data from one system to another, known as data migration, is a critical task. As big data continues to grow, organizations encounter increasing complexity in managing data migration. While Apache Spark is an effective open-source big data processing framework that provides a versatile platform for data migration, there are also other tools and frameworks available, such as Apache NiFi, Kafka, Hadoop, and Amazon Warehouse Services (AWS) Glue. This paper explores data migration using Apache Spark alongside other widely used tools and frameworks, offering a comprehensive overview of each tool, and highlighting their strengths and weaknesses. The study includes a real-world performance-based case study, evaluating the data migration capabilities of each tool and providing detailed statistics for comparison. The results demonstrate that Apache Spark surpasses the other tools in terms of data transfer rates, processing times, and fault tolerance capabilities. Additionally, this paper refers to a randomized online algorithm to optimize costs for user-generated data stored in clouds with hot or cold migration, without requiring any future information. The algorithm achieves a guaranteed competitive ratio and can be extended with prediction windows when short-term predictions are reliable.
In the modern world that relies heavily on data, data migration has become an integral process for organizations to adapt to changing business requirements. Data migration involves moving data from one system to another, which can be a complicated and time-consuming process. As the volume, speed, and variety of data continue to expand, the selection of the appropriate tool for data migration has become more crucial than ever before.
Apache Spark is a potent open-source big data processing frame- work that provides a flexible platform for data migration. With its distributed computing capabilities, Spark can process vast amounts of data in a parallel and fault-tolerant manner. Addition- ally, Spark supports various data formats, including structured, semi-structured, and unstructured data, making it a versatile tool for data migration. A comparative study of data migration using different tools and frameworks can provide organizations with valuable insights into the pros and cons of each tool and help them choose the most appropriate tool for their specific requirements [1].
Warm data migration is a strategic approach to managing data that balances the need for accessibility with cost efficiency, mak- ing it suitable for various business-critical applications and sce- narios where continuous service is essential [1]. This approach sits between hot and cold storage, providing a middle ground that ensures data is readily accessible without incurring the high costs associated with hot storage.
Storage-as-a-Service (STaaS) clouds generally offer both hot and cold storage tiers with different pricing options. Hot tiers provide a higher storage price but a lower access price, and vice versa for cold tiers. Many studies show that user-generated data generally receive relatively high access frequency in the early period of their lifetimes while the overall trend of accesses is downward. Thus, when such kinds of data are hosted in clouds, they can be stored in hot tiers initially and then migrated to cold tiers for op- timizing costs. However, the cost of migration is non-negligible, and the number of accesses may then unexpectedly increase after migration, which indicates that a rash migration will incur more costs instead of cost-savings. For making optimal migration de- cisions, future data access curves are needed, but it is generally very hard to predict them precisely. To solve this problem, this paper refers to a randomized online algorithm to optimize costs for those user-generated data stored in clouds, without requiring any future information. The referenced algorithm can achieve a guaranteed competitive ratio and can be easily extended with prediction windows when short-term predictions are reliable [2].
According to the Cloud Storage Market Research Report, the STaaS market is expected to increase from $32.72 billion in 2019 to $106.71 billion by 2024 with an average annual growth rate of 23.76% over the anticipated period, and it will finally reach $207.05 billion by 2026 [2]. Therefore, STaaS cost management becomes a major problem confronted by multiple user groups, including small, medium, and large enterprises. For users who store their data in STaaS clouds, their expenses mainly include data storage cost and access cost. When providing Object Storage services, current main STaaS providers, such as Google Cloud Storage, Microsoft Azure, and Amazon S3, generally offer multiple storage tier options and pricing policies for users to select accord- ing to their specific data storage and access situations. Hot and cold tier storage options discussed above offer an opportunity of saving cost concerning a specific kind of data posted on the Internet, which is user-generated content (UGC), such as contents on YouTube, Facebook, and Twitter [3]. This is because the access patterns of a mass of UGC data have a long-tail phenomenon, which means that for each data object, most accesses or requests occur in the early period of its lifetime while only a handful of accesses occur during its long remaining lifetime. That is, such data objects are in hot status at the beginning of their lifetime and gradually get cold as time goes on. Through theoretical analysis, referenced randomized online algorithm is cost guaranteed and its competitive ratio is;(1)dealing with UGC data [2].


Graph 1: Comparison of Data Transfer Rates
This study presents a detailed comparative analysis of data migration using Apache Spark and other popular tools and frameworks, including Apache NiFi, Kafka, Hadoop, and AWS Glue [1]. The performance of each tool was evaluated based on data transfer rates, processing times, and fault tolerance capabilities using a real-world data set.

Results
The results of the performance evaluation demonstrated that Apache Spark outperformed the other tools in terms of data transfer rates, processing times, and fault tolerance capabilities.
Hadoop and AWS Glue also performed well but had higher CPU and memory usage compared to Spark. Apache NiFi and Kafka had longer data migration times and higher resource usage, mak- ing them less suitable for large-scale batch data migration [1].

Figure 2: Example Policy to Move Data to AWS S3 Glacier
Storage-as-a-Service (STaaS) clouds generally offer both hot and cold storage tiers with different pricing options. Hot tiers provide a higher storage price but a lower access price, and vice versa for cold tiers. To optimize costs, this paper proposes a randomized online algorithm that does not require future information. The referenced algorithm achieves a guaranteed competitive ratio and can be extended with prediction windows when short-term predictions are reliable.
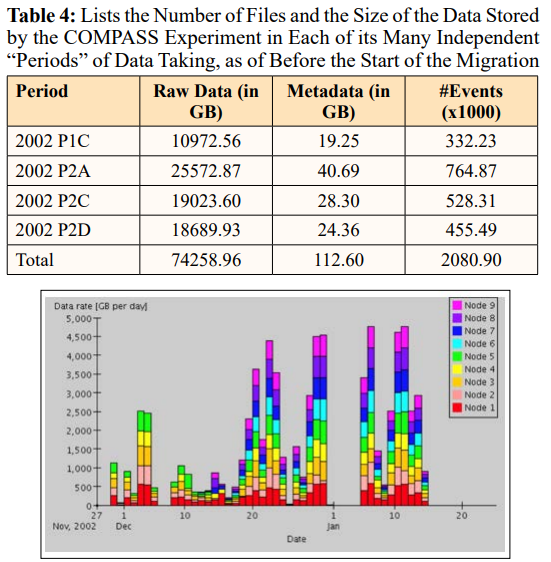
The migration of the data collected by the Common Muon and Proton Apparatus for Structure and Spectroscopy (COMPASS) ex- periment at Conseil Européen pour la Recherche Nucléaire (CERN) is a prime example of large-scale data migration. In less than three months, almost 300 TB of data was migrated at a sustained data rate approaching 100 MB/s, using a distributed system with multiple nodes and data servers. This project, carried out by the Database Group of CERN’s IT Division, involved both a physical media migration, from Storage Tek 9940A to Storage Tek 9940B tapes, and a data format conversion, from an Object Database Manage- ment System to a hybrid persistency mechanism based on flat files referenced in a Relational Database Management System [4].
High Energy Physics (HEP) experiments, such as COMPASS, require large amounts of data storage. The data accumulated by these experiments, referred to as "event data," records the response of complex electronic devices to high-energy particle interactions. The physics community expects all the data collected by HEP experiments to remain available for reprocessing and analysis for many years after the end of data taking [4]. This necessitates large-scale data migrations whenever support for the physical medium or the algorithms used to store the data is discontinued.
Because of the rapid evolution of hardware and software tech- nologies for data storage, the need to perform large-scale data migrations is common to all projects that critically depend on the long-term availability of their data [4]. High-energy physics experiments, with their huge amounts of data and high manpower and material costs, are only one such example. The migration of the 300 TB of data collected by the COMPASS experiment at CERN has been presented [4].
Recent analyses report that many sectors of our economy and society are more and more guided by data-driven decision pro- cesses (e.g., healthcare, public administrations, etc.). As such, Data Intensive (DI) applications are becoming more and more important and critical. They must be fault-tolerant, they should scale with the amount of data, and be able to elastically leverage additional resources as and when these last ones are provided. Moreover, they should be able to avoid data drops introduced in case of sudden overloads and should offer some Quality of Service (QoS) guarantees.
Ensuring all these properties is, per se, a challenge, but it becomes even more difficult for DI applications, given the large amount of data to be managed and the significant level of parallelism required for its components. Even if today some technological frameworks are available for the development of such applica- tions (for instance, think of Spark, Storm, Flink), still lack solid software engineering approaches to support their development and, in particular, to ensure that they offer the required properties in terms of availability, throughput, and data loss.
This implies the need for highly skilled persons and the execu- tion of experiments with large data sets and many resources, and, consequently, a significant amount of time and budget. To achieve the desired level of performance, fault tolerance, and recovery, it had to adopt a time-consuming, experiment-based approach, which, in our case, consisted of three iterations: the design and implementation of a Mediation Data Model capable of managing data extracted from different databases, the improvement of per- formance of our prototype when managing and transferring huge amounts of data; the introduction of fault-tolerant data extraction and management mechanisms, which are independent from the targeted databases [1,4].
Choosing the right tool for data migration is critical to ensure the success of the migration process. Apache Spark emerged as the best solution for data migration based on its performance, scalability, and user-friendliness. Additionally, the referenced randomized online algorithm provides a cost-effective solution for managing user-generated data in cloud storage.
It is important but challenging for STaaS cloud users to make decisions on when to migrate data objects to cold storage tiers to optimize costs, as the overall trend of accesses is downward, while users do not know exact future access curves. A randomized online algorithm with two density functions can guide STaaS cloud users to make decisions on when to migrate objects to cold storage tiers without knowledge of their future access curves. Theoretically, this randomized online algorithm can achieve a guaranteed competitive ratio of:

This algorithm can be extended with a prediction window when short-term predictions are reliable.
The problem of optimizing the monetary cost spent on storage services when data-intensive applications with time-varying workloads are deployed across data stores with several storage classes was also studied. An optimal algorithm was proposed, but due to its high time complexity, a new heuristic solution formulated as a Set Covering problem with three policies was introduced. This solution takes advantage of pricing differences across cloud providers and the status of objects that change from hot-spot to cold-spot during their lifetime and vice versa. The evaluation results demonstrate that this solution is capable of reducing the cost of data storage management by approximately two times in some cases when compared to the widely used benchmark algorithm in which the data are stored in the closest data store to the users who access them [5].
Future work should explore new algorithms to optimize costs for objects with more than two statuses (e.g., cold, warm, and hot). Additionally, the home data center can be selected based on the mobility of the users, affecting the response time of the Gets/Puts issued by client data centers. Using a quorum-based model for data consistency provides stronger consistency semantics compared to eventual consistency. To determine the gap between the proposed optimal and heuristic algorithms in cost performance, it is required to compute the competitive ratio defined as the ratio between the worst incurred cost by the heuristic algorithm and the cost incurred by the optimal algorithm. This involves computing the upper-bound cost for the optimization of replicas migration and replica placement based on covered load volume.