Author(s): Premkumar Ganesan
Cloud-based disaster recovery (CBDR) has become essential for modern organizations seeking scalable, cost-efficient, and reliable solutions for business continuity. This paper delves into the various aspects of CBDR, exploring key strategies, methodologies, and cloud services that help minimize risks, ensure data protection, and improve operational continuity. Using cloud technologies such as Amazon Web Services (AWS), Google Cloud, and Microsoft Azure, organizations can achieve faster recovery times, automated backups, and comprehensive failover mechanisms. Additionally, the paper discusses the challenges associated with CBDR, such as data security, regulatory compliance, and system complexities. Through case studies and industry references, this paper highlights best practices for implementing successful cloud-based disaster recovery strategies, with a specific focus on AWS's whitepaper and Google Cloud's backup and disaster recovery deployment plan.
In today’s digital-first business landscape, organizations are increasingly dependent on data and computing infrastructure. Any disruption, whether due to cyberattacks, hardware failure, or natural disasters, can lead to significant financial losses, productivity setbacks, and data breaches [1]. Business continuity is at risk if disaster recovery strategies are not aligned with modern technological advancements. Traditional disaster recovery solutions have largely relied on on-premises hardware and infrastructure, which are costly and difficult to scale [2]. These methods require significant capital investments in maintaining redundant data centers and physical backup systems, often leading to inefficiencies during times of disaster recovery. Cloud-based disaster recovery (CBDR) offers a modern alternative that leverages cloud services for cost-efficient, scalable, and automated recovery solutions [3]. With CBDR, organizations can replicate data and applications in the cloud and recover quickly after a disruption. This paper explores key aspects of CBDR, with a focus on its application in platforms like Amazon Web Services (AWS), Google Cloud, and Microsoft Azure. Additionally, this paper includes AWS's whitepaper on disaster recovery options and Google Cloud’s Backup and Disaster Recovery deployment plan [4,5].
Cloud-based disaster recovery is built around several key components that enable rapid and efficient recovery after a disaster. The following subsections explain these components in detail:
One of the fundamental elements of CBDR is data replication. Cloud services such as AWS, Google Cloud, and Azure provide automated data replication across multiple regions. This ensures that data remains accessible and recoverable, even if one data center experiences an outage [6]. For example, AWS offers the Amazon S3 Cross-Region Replication service, while Microsoft Azure provides Geo-Redundant Storage (GRS), which automatically replicates data to another region for disaster recovery purposes [7,8]. Google Cloud similarly provides Cloud Storage Multi- Regional options that ensure automatic redundancy across different regions [9]. Data backup further ensures that historical versions of data can be retrieved to avoid data corruption or loss. Services like AWS Backup, Azure Backup, and Google Cloud Backup and DR simplify this process by automating data backup and recovery, enabling businesses to recover data in minutes after a failure [10,11]. Google Cloud’s Backup and Disaster Recovery deployment plan outlines best practices for deploying disaster recovery solutions. It emphasizes the importance of automating backup processes, setting up regular backup intervals, and ensuring data encryption both at rest and in transit [5].
Failover is the process of automatically switching to a backup system or server when the primary one fails. AWS Elastic Disaster Recovery provides failover and failback solutions that enable companies to recover entire applications within minutes after a disaster by redirecting traffic to alternative environments [12].
Microsoft Azure provides Azure Site Recovery (ASR), which orchestrates replication and failover to ensure business continuity by managing workloads in the cloud [13]. Google Cloud provides a Global Load Balancer, which handles traffic redirection across regions in case of an outage [14]. This automated failover ensures that the system remains available even during regional failures. In Google Cloud’s deployment plan, it is recommended to set up multi-site failover architectures to minimize downtime and ensure smooth failback processes. It also suggests implementing automated health checks for failover systems [5].
The Recovery Time Objective (RTO) defines how quickly a business needs to restore services following a disaster, while the Recovery Point Objective (RPO) defines the maximum tolerable period during which data might be lost [15]. AWS, Azure, and Google Cloud provide tools to help businesses achieve optimal RTO and RPO. AWS’s Elastic Load Balancer and Route 53 DNS service allow businesses to quickly redirect traffic to healthy resources, ensuring low RTO, while continuous backup solutions in AWS, Azure, and Google Cloud reduce RPO to seconds [16-18].

Figure 1: Recovery Objectives [4]
Google Cloud’s backup and disaster recovery deployment plan highlights the importance of pre-defining RTO and RPO goals to tailor disaster recovery strategies based on the criticality of business systems. By using Google Cloud Operations Suite, businesses can continuously monitor and improve recovery times [5].
One of the most significant advantages of CBDR is its cost- efficiency. Traditional disaster recovery systems require the setup and maintenance of redundant data centers, which can be prohibitively expensive. CBDR operates on a pay-as-you- go model, significantly reducing both capital and operational expenditures [19]. For example, businesses using AWS, Azure, or Google Cloud only pay for storage and compute resources when needed for disaster recovery [20]. AWS’s whitepaper emphasizes cost efficiency through tiered storage options such as Amazon S3 Glacier and Amazon S3 Glacier Deep Archive, which are designed for infrequently accessed data, further reducing costs [4]. Similarly, Google Cloud’s deployment plan highlights the use of archive storage for long-term data retention and disaster recovery purposes [5].
Cloud-based solutions allow businesses to dynamically scale their disaster recovery systems. This means that as business needs grow, cloud infrastructure can be expanded without the need to invest in additional hardware. Both AWS, Azure, and Google Cloud offer scalable disaster recovery solutions, allowing businesses to seamlessly increase their capacity to meet demand [21].
AWS’s whitepaper highlights the use of Auto Scaling and Elastic Beanstalk, which allow for flexible scaling and ensure that disaster recovery environments can be scaled up or down based on real- time needs [4]. Google Cloud’s deployment plan recommends dynamic scaling configurations using Compute Engine and Google Kubernetes Engine (GKE) to handle increased workloads during a disaster event [5].
Cloud platforms offer geographic redundancy, where data and applications are replicated across multiple geographic locations to minimize the impact of localized disasters [22]. AWS’s Global Infrastructure spans across multiple regions and availability zones, ensuring that businesses can switch to alternative regions if one region is affected by an outage [23]. Similarly, Google Cloud’s Global Load Balancer and Azure Geo-Redundant Storage (GRS) enable businesses to maintain high availability by balancing traffic across global data centers [24,25]. Google Cloud’s deployment plan further explains the use of multi-region deployments to ensure continuous availability during regional outages, allowing organizations to maintain high availability during failures [5].

Figure 2: AWS Disaster Recovery Strategies [4]
AWS offers a comprehensive suite of disaster recovery solutions, including:
Google Cloud offers a range of disaster recovery options:
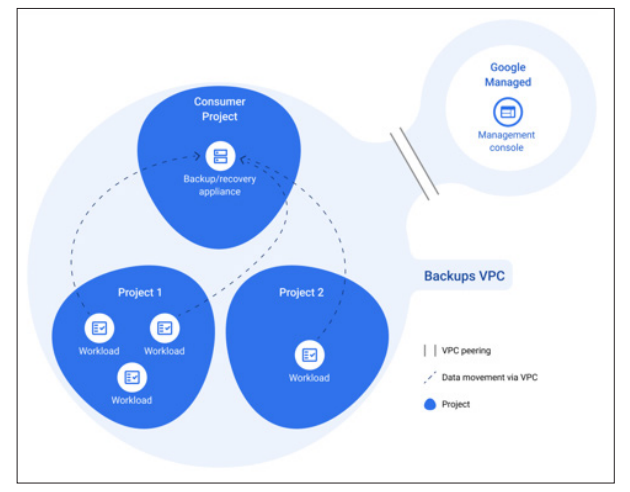
Figure 3: Goggle Cloud Backup and Recovery [5]
Azure provides a highly integrated disaster recovery solution, which includes:

Figure 4: Azure Site Recovery [13]
While cloud platforms offer robust security measures, businesses still face challenges related to data security and compliance. It is essential to implement data encryption, multi-factor authentication (MFA), and regular security audits to protect sensitive information [36]. Regulatory compliance such as GDPR and HIPAA adds an extra layer of complexity, especially when replicating data across multiple regions with varying regulations [37]. Google Cloud’s disaster recovery deployment plan highlights the importance of automated encryption, ensuring compliance through the Cloud Key Management (KMS) service, which provides centralized control over encryption keys [5].
Effective cloud-based disaster recovery relies on sufficient network bandwidth. Large-scale data replication and recovery processes can strain network resources, particularly during real-time failover and failback events [38]. Businesses must ensure that their internet and network infrastructure can support these requirements to avoid latency issues during recovery. Google Cloud’s deployment plan addresses this challenge by recommending network optimization strategies such as high-bandwidth VPNs and Cloud Interconnect to ensure minimal latency during failover operations [5].
Cloud-based disaster recovery is an essential tool for modern businesses aiming to reduce risk and ensure continuity during disasters. By leveraging cloud platforms like AWS, Google Cloud, and Microsoft Azure, organizations can implement scalable, flexible, and cost-effective disaster recovery solutions. However, it is critical to address challenges such as data security and bandwidth limitations. With proper planning, regular testing, and adherence to best practices, CBDR can significantly enhance an organization's resilience in the face of unforeseen disruptions.