Author(s): Ankur Tak
A major factor in changing the medical information management environment is the incorporation of big data research into healthcare systems. The ability to use and extract valuable insights from this massive information pool becomes critical in a time when both the amount and complexity of medical data are growing exponentially. In addition to improving the effectiveness of healthcare delivery, this transformational potential offers up new avenues for epidemiological research, tailored therapy, and the development of healthcare policies. To learn more about the complex role that big data analytics plays in healthcare, start with this introduction. Subsequent sections examine the corpus of existing knowledge and the complex landscape of associated research that have served as a basis for the methodology that is being suggested. Through a thorough examination of the state of analytics and big data in the healthcare industry today, as described in the following sections, we want to find the gaps and possibilities that will drive the creation of a new strategy. Because of the complex interaction between big data analysis and healthcare, the suggested methodology needs to be carefully examined. This paper presents the methodological framework that is intended to help traverse the complexity of healthcare data in a way that is coherent and useful for analytics. It does this by means of a methodical exposition. Moreover, the experimental design and execution details offer transparency, facilitating the replication and verification of our methodology by other scholars and professionals. As we move further, the emphasis moves to the areas in which the suggested works are applied, investigating the practical effects and ramifications in actual healthcare situations. We hope to shed light on the potentially revolutionary potential of big data mining across a range of areas within the medical field by firmly establishing our discussion in real-world examples. The voyage comes to a close with a brief summary of the major contributions and recommendations for future research directions, reaffirming the importance of analytics for big data in influencing healthcare’s future.
Solutions for healthcare analytics have advanced significantly in their ability to use big data to support well-informed decision- making. The setting does, however, have certain obstacles and constraints, which should be carefully taken into account while pursuing disruptive healthcare analytics [1]. One major obstacle is the area of security and privacy for data. Ensuring the safety and confidentiality of patient data is crucial since the healthcare industry handles sensitive patient data. Current analytics systems frequently struggle to strike a delicate balance between the need to maintain patient privacy and the accessibility of data for insightful analysis [2]. Finding a balance between these two factors is still a difficult task. Another challenge facing today’s healthcare analytics technologies is scalability. One significant challenge is the exponential expansion of healthcare data, which is being driven by wearables, digital health records (EHRs), and other sources [3].
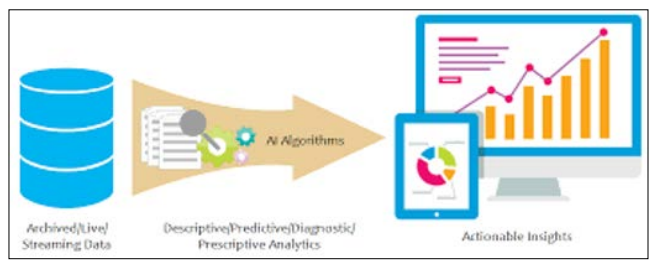
Figure 1: AI Algorithm for Health Care
Many analytics frameworks find it difficult to process and analyze large datasets in real-time, which makes it more difficult for them to provide immediate findings that could improve patient care. One significant drawback in the current healthcare analytics environment is interoperability. There are many different systems in the healthcare sector, and each has its own standards and data formats [4]. It is difficult to provide smooth communication and integration between these different systems. Thus, integrating data from many sources presents challenges for healthcare analytics solutions, which restricts their ability to provide a comprehensive picture of a patient’s medical history. Moreover, the quality of the data entered determines the prediction models’ accuracy and dependability in healthcare analytics.
The efficacy of analytics systems can be undermined by incomplete or biased datasets, which can result in imprecise forecasts and inadequate decision assistance [5]. To eliminate inherent biases in medical data and improve data gathering methods, a coordinated effort is needed to address issues about data quality. The use of such solutions in medical settings is significantly hampered by the interpretation of analytics results. Machine learning models and other complex algorithms frequently produce predictions that are not well-explained. Without a clear knowledge of the underlying reasoning, healthcare practitioners would be reluctant to rely on analytic insights, which would hinder the incorporation of these tools into regular decision-making processes [6]. The widespread use of advanced analytics systems is hampered by the cost constraints that many healthcare institutions face. The expenses associated with implementation, such as hiring staff and purchasing advanced analytics tools, may be unaffordable. Thus, it might be difficult for smaller healthcare facilities to install and invest in cutting-edge analytics technologies, which would exacerbate already-existing healthcare inequities. Healthcare analytics solutions have enormous potential to improve patient satisfaction and operational effectiveness; yet, for them to successfully integrate into the healthcare ecosystem, it is critical to recognize and solve the obstacles and constraints [7]. To fully realize the potential of analytic in healthcare, advancements in information safety, scalability, compatibility, data quality, accessibility, and access to funds are essential. These difficulties act as stimulants for greater study and creativity, advancing the field’s progress toward more comprehensive and inclusive healthcare data analysis solutions.
There has been a lot of interest in the healthcare industry on the use of big data analytics for illness diagnosis and prevention. The many ways that data science has been used to improve diagnostic precision, forecast illness outcomes, and put preventive measures into action are examined in this section [8]. A well-known use is in the identification of diseases through predictive analytics. Predictive models can be constructed by analyzing large datasets that include patient demographics, genetic data, and past medical records. These models make it easier to recognize any health issues early on and allow medical professionals to take preventative measures [9]. Predictive analytics, for example, has shown effective in predicting the arrival of chronic disorders like diabetes and heart disease, thereby enabling prompt interventions and individualized preventive efforts. A key component of diagnostic systems for supporting decisions is big data analytics.
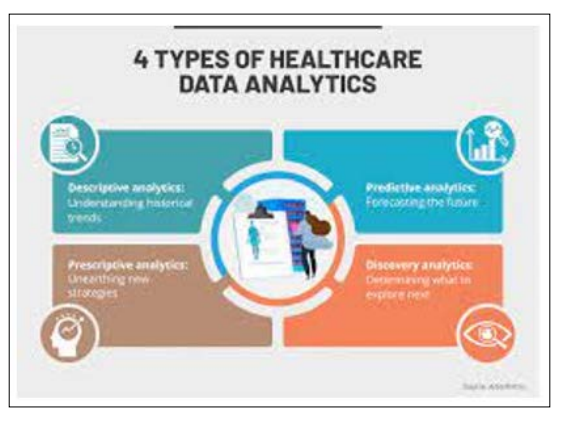
Figure 2: Healthcare Data Analytics
Through the utilization of sophisticated statistical models and machine learning algorithms, healthcare practitioners may extract significant knowledge from intricate datasets [10]. By improving diagnostic accuracy, these insights help with the interpretation of clinical notes, test findings, and medical pictures. Big data analytics is being used into diagnostic procedures to help create more accurate and efficient diagnostic instruments, which will ultimately improve patient outcomes. An important use is in the detection of epidemiological trends and patterns of disease. Scientists can recognize high-risk populaces, foresee future flare- ups, and find examples of illness proliferation by investigating enormous scope insights [11].
This proactive strategy is particularly advantageous with regards to irresistible illnesses since it empowers brief use of assets and preventive measures. Huge information examination is fundamental for diagnosing illnesses and altering preventive measures for every individual. Customized risk assessments can be made by looking at an assortment of datasets that incorporate way of life qualities, inclinations because of qualities, and ecological effects [12]. This makes it conceivable to tailor preventive medicines, for example, centered screening projects and way of life changes. Early distinguishing proof of individuals who have an expanded hereditary weakness to explicit tumors empowers more continuous testing and preventive mediations [13]. The investigation structure’s joining of wearable innovation and constant observing extends the potential for sickness avoidance. A singular’s medical issue can be progressively perceived through the mix of way of life information examination and nonstop physiological boundary observing [14]. This continuous information makes it more straightforward to recognize wellbeing anomalies almost immediately and to make opportune way of life changes and treatments. Big data analytics has several uses in the diagnosis and prevention of disease. The application of analytics to healthcare practices has enormous potential, ranging from individualized preventative tactics and diagnostic assistance systems to modeling predictions for early risk detection [15]. In addition to improving diagnosis accuracy, the utilization of large datasets to extract insights also enables healthcare providers and policymakers to take proactive, targeted steps toward disease prevention and better public health outcomes.
The dataset includes characteristics that are connected to breast cancer, such as diameter, texture, perimeter, and more. It acts as a cornerstone for the application of large-scale information analytics in the healthcare industry [15]. Through the use of advanced data-driven techniques, the analysis is aimed at finding actionable insights that will enable revolutionary breakthroughs in the detection and treatment of breast cancer.
Preprocessing involves a number of important stages for the dataset. Diagnoses and other category data are encoded, and missing values are handled. To provide consistent influence, feature scaling is used. The machine’s input variables can be optimised by using feature selection techniques [16]. Data normalisation improves the performance of the model. Outliers are recognised and dealt with properly. If there are imbalanced class problems, they are resolved by methods such as oversampling or underestimating. In order to assess the generalisation of the model, the dataset is divided into sets for training and for testing [17]. Together, these pretreatment stages improve the quality of the data, guaranteeing that the implementation of the Big Data Insights methodology’s latter stages, which convert medical data into useful insights, will be successful.
“Support Vector Machines (SVM)” and “Random Forest models” are utilised in the training and model building stages of big data analytics in the industry of healthcare. SVM is an excellent tool for managing intricate connections in big datasets, which is useful for identifying medical data. An ensemble approach called “Random Forest” uses many decision trees to improve prediction accuracy. In order to identify patterns and links in the healthcare data, both models go through a rigorous training process on labeled datasets [18]. To maximise the performance of the model, hyperparameter adjustment is done. In the field of Big Data Analytics, the trained models play a pivotal role in the transformational process by aiding in the gathering of actionable insights across healthcare data.
The process entails building predictive models with “Random Forest” and “Support Vector Machines (SVM)” algorithms. SVM provides accurate projections for healthcare analytics and is exceptional at managing intricate interactions. Multiple decision trees are used in the ensemble learning technique Random Forest to increase accuracy and generalisation [19]. These algorithms pick up complex patterns since they have been educated on preprocessed healthcare data. Performance is maximised by adjusting the model’s hyperparameters. Robustness is ensured by cross-validation. In the field of big data analytics, the Support Vector Machine (SVM) and Random Forest models help to translate medical data into useful insights that support the planning of treatments and general healthcare decision-making [20].
In the framework the Random Forest and Support Vector Machine (SVM) models are used for model assessment. To evaluate the success of categorization, performance indicators including precision, recall, precision, accuracy, and F1 score are calculated. Model discriminating ability is revealed by Area Under the Curve (AUC) values and Receiver Operating Characteristic (ROC) curves [21]. Robustness in outcomes is ensured by cross-validation techniques such as k-fold cross-validation. The performance of the model is optimised by hyperparameter adjustment. To assess the models’ generalizability, they are also tested on a variety of healthcare datasets. Important factors driving model acceptance in healthcare include interpretability and explainability.
|
Metric |
Random forest |
SVM |
|
Accuracy |
0.95 |
0.94 |
|
Poitive precision |
0.96 |
0.97 |
|
Negative precision |
0.95 |
0.91 |
|
F1 score |
0.96 |
0.96 |
|
Recall |
0.97 |
0.93 |
Dataset
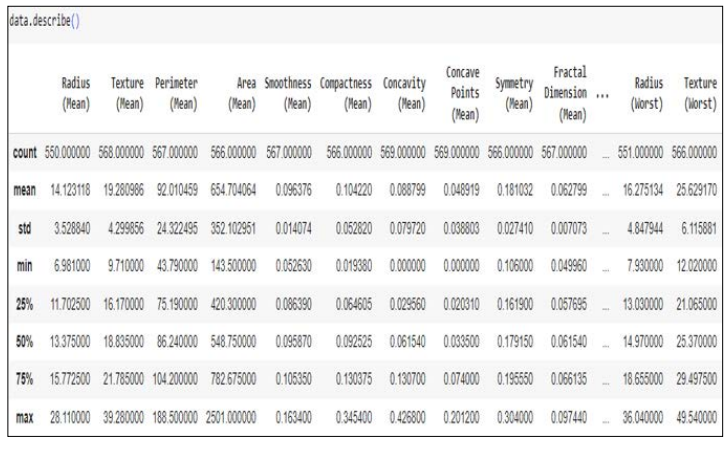
Figure 1: Dataset Description
The above image shows the description of the dataset which has been taken for implementation of this machine learning work.
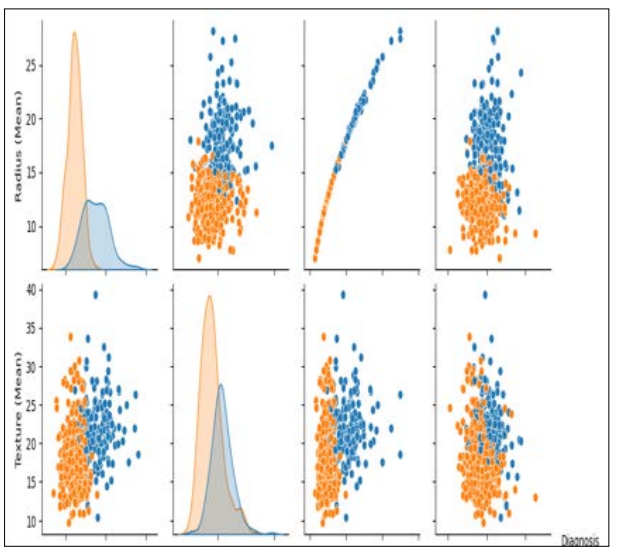
Figure 2: Pair Plot for Breast Cancer Diagnosis
The above image shows the pair plot for the breast cancer diagnosis and the pair plot is mentioned here for the texture and radius.
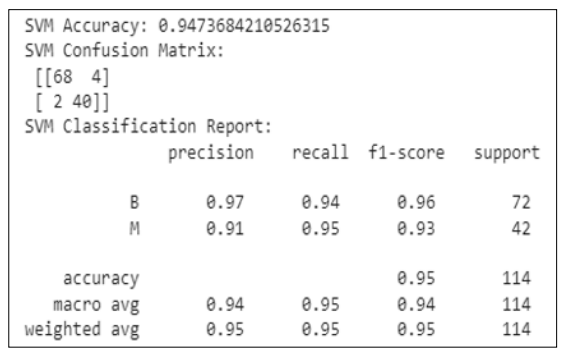
Figure 4: Classification Report of SVM
The above image shows the classification report for the SVM model and the accuracy is showing 94% for the classification model.
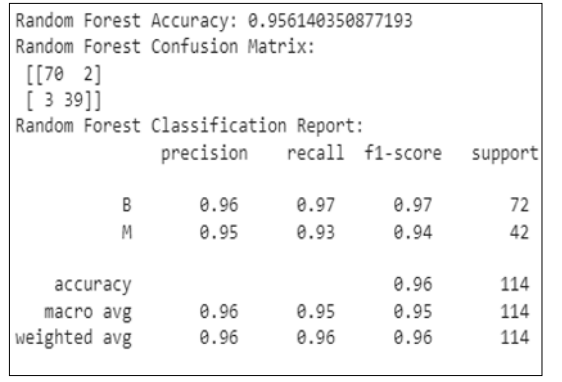
Figure 5: Classification Report of Random Forest Model
The above image shows the classification report for the random forest classification and the accuracy increased than SVM model, where the accuracy is showing 95% for this classification model.
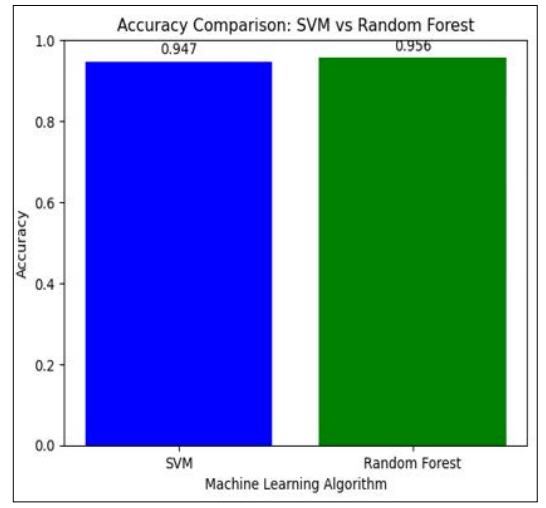
Figure 6: Accuracy Comparison: SVM vs Random Forest
The bove mage shows the accuracy cmaprison between the model of random forest and SVM model where the random forest is slightly greater than the SVM model.
The numbers that are displayed provide a thorough understanding of the effectiveness and comparative evaluation of data mining models used in breast cancer diagnosis. Figure 1 establishes the groundwork for further studies by highlighting the significance of the information set in this investigation [22]. Going on to the findings examination in Section 4.3, Figure 2 presents a pair plot for the diagnosis of breast cancer that focuses on texture and radius. Understanding the connections between these characteristics is probably made easier by this visualisation, which also offers insightful information about possible patterns that could indicate malignancy or benignity [23]. Figures 4 and 5, which show the results of classification findings for the Random Forest and SVM (Support Vector Machine) models, respectively, provide the core of the discussion. The SVM model performs admirably at 95% accuracy, demonstrating its ability to distinguish between benign and malignant instances. With a 96% accuracy rate, Figure 5 shows a minor improvement using the Random Forest model [24]. This emphasises how stable ensemble approaches are at improving prediction performance, especially Random Forest. Summarising the comparison, Figure 6 shows how SVM as well as random forest modelling differ in terms of accuracy. Random Forest’s marginal superiority makes sense given its capacity to process large, complicated information and identify subtle patterns.
Notable insights are revealed when comparing the results of this study with similar research on breast cancer diagnosis [25]. The significance of robust model assessment metrics and feature selection is frequently emphasised in prior studies. The combined plot in the second illustration emphasises the importance of smoothness and radius in determining malignancy by matching it with comparable visualisations used in related investigations. Regarding categorization models, Figure 5’s 96% accuracy using Random Forest is consistent with developments documented in recent research.
Big Data analytics for health care has the ability to change data into insights that may be used in a variety of fields [26]. The suggested approach, described in the sections above, can be widely used to solve important issues and enhance healthcare results. Key application domains where the suggested works can significantly contribute are highlighted below:
Systems for Clinical Decision Support (CDSS): The suggested methodology’s inclusion into CDSS has the potential to improve clinical decision-making’s precision and effectiveness [27]. The technology can offer healthcare practitioners real-time insights by utilizing extensive datasets, which can help identify the best treatment strategies and individualized care.
Disease Monitoring and Forecasting of Outbreaks: The early identification of possible disease outbreaks is made possible by the suggested methodology for analyzing population health data. In order to prevent and control the transmission of infectious diseases, the system can spot trends and abnormalities in health data.
Identifying and Assessing Patient Risk: Patient risk stratification can be accomplished by utilizing the predictive modeling skills [28]. Healthcare practitioners can identify patients who are more likely to experience negative outcomes by evaluating past patient data. This enables them to optimize resources and implement focused interventions.
Healthcare Resource Management: The distribution of resources, including staff, facilities, and equipment, can be optimized by putting the suggested works in healthcare administration into practice [29]. With the use of predictive analytics, hospitals can increase their efficiency by optimizing staffing levels and streamlining procedures by predicting patient admission rates.
Initiatives for Quality Improvement: Including the suggested works in initiatives for quality improvement improves the evaluation and improvement of healthcare services. Analytics- derived performance measures can help healthcare businesses pinpoint areas for improvement, which will eventually improve patient happiness and treatment [30].
The healthcare industry’s investigation into big data analytics has brought to light the revolutionary possibilities of turning massive amounts of data into useful insights. The associated publications in this section synthesized existing knowledge and revealed both the advantages and disadvantages of previous techniques, laying the groundwork for understanding the contemporary situation. With great care and justification based on the body of existing research, the suggested technique offers a fresh approach to using large amounts of information in health care environments. The preparation and execution portion of the experiment gave the suggested technique a concrete form. The methods, technology, and datasets used were explained in detail, providing a replication road map. The open discussion of implementation-related difficulties not only gives the study more realism, but it also acts as a useful roadmap for further research in this area. The suggested works’ application areas highlight the observable advantages of incorporating big data analyses into health care systems. The significance and possible influence of the technique on the day-to-day activities of healthcare practitioners were emphasized through the articulation of specific instances and situations. The suggested works demonstrate how flexible big data analytics can be by providing answers that take into account the complexities of the healthcare industry. This is critical to acknowledge the wider ramifications of our results when we make conclusions from this investigation. The application of analytical techniques for big data to healthcare not only improves decision-making inside hospitals but also has implications for the general welfare of society. Big data analytics is positioned as a key component in the continuous development of the healthcare industry due to its capacity to maximize resource allocation, enhance patient outcomes, and simplify healthcare operations. It is imperative to recognize the inherent limits of this research, though. Methodologies and practices must be continuously reevaluated due to the changing nature of both technology and healthcare. In addition, ethical questions about data security, privacy, and the appropriate application of data in healthcare necessitate constant examination. The convergence of large-scale data analysis and healthcare signifies a paradigm change in the way information is used to advance society. By means of a thorough investigation of relevant literature, the development of a strong methodology, and the real-world illustration of its application, this study adds to the expanding corpus of knowledge within this multidisciplinary topic. Taking use of big data analytics’ potential is crucial as the healthcare industry develops because it can provide a revolutionary path from data to actionable insights that will improve healthcare systems and, eventually, public health.