Author(s): <p>Vandana Sharma</p>
Artificial Intelligence (AI) has become a cornerstone in the realms of fraud detection and personalization within various industries. This article delves into the multifaceted applications of AI in these domains, exploring how machine learning algorithms are reshaping security measures by detecting fraudulent activities and simultaneously enhancing user experiences through personalized recommendations.
As the digital landscape continues to evolve, so do the methods employed by malicious actors to exploit vulnerabilities. Simultaneously, consumers expect more personalized and seamless experiences. In response to these challenges, Artificial Intelligence has emerged as a powerful tool, playing a pivotal role in fortifying security measures against fraud and elevating user experiences to unprecedented levels.
Fraud detection is a critical aspect of maintaining the integrity of financial transactions and protecting both businesses and consumers from malicious activities. Artificial Intelligence (AI) has emerged as a powerful ally in this realm, leveraging advanced algorithms and real-time data analysis to identify and respond to fraudulent activities. Here’s an in-depth exploration of the key components:
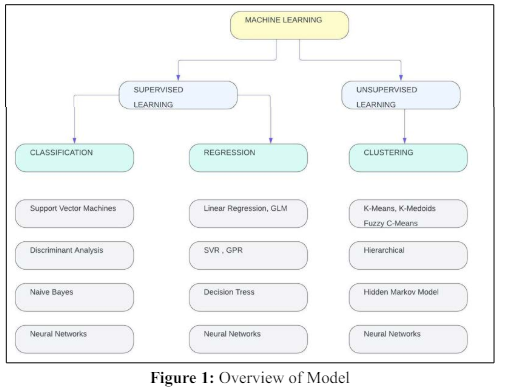
AI-driven fraud detection heavily relies on machine learning algorithms, employing both supervised and unsupervised learning approaches.
This approach involves training a machine learning model on labeled datasets, where historical transactions are categorized as either legitimate or fraudulent.
In real-time, the model can analyze new transactions and predict whether they align with the learned patterns of fraud or legitimacy
Implementation Details
Unsupervised learning is particularly effective in anomaly detection, where the algorithm identifies irregular patterns in data without predefined labels.
It’s beneficial for detecting new and previously unseen types of fraud.
Predictive modeling involves the use of historical data to build models capable of predicting potentially fraudulent activities based on evolving patterns.
Models are trained to predict the likelihood of a transaction being fraudulent based on historical patterns and evolving trends.
Predictive models operate in real-time, continuously learning from new data to enhance accuracy. Example: Time-series analysis can be used to predict when certain types of fraud are likely to occur based on historical patterns.
Real-time data analysis is a crucial component of AI-driven fraud detection, enabling immediate responses to potential threats.
AI systems analyze vast datasets in real-time, allowing for the swift identification of suspicious patterns or activities.
Immediate response mechanisms, such as transaction blocking or user authentication challenges, can be triggered in real-time. Example: Streaming analytics platforms enable the continuous analysis of transactions as they occur, providing instant insights.
Machine learning (ML) plays a pivotal role in the field of fraud detection by actively enhancing both the accuracy of detection mechanisms and the speed at which potential fraud is identified and addressed. This section explores the key elements within this domain:
Adaptive learning models are at the core of ML-driven fraud detection, ensuring that the system evolves and improves its accuracy over time.
Adaptive learning models refer to ML algorithms that continuously learn and update their understanding of patterns based on new data.
The quality and diversity of training datasets are paramount for ensuring the effectiveness of machine learning models in fraud detection.
Training datasets are sets of historical data used to teach ML models to recognize patterns associated with legitimate and fraudulent transactions.
Collect comprehensive historical data that spans various transaction types, user behaviors, and time periods.
Cleanse and preprocess the data, handling missing values, outliers, and ensuring a representative sample.
Categorize transactions as legitimate or fraudulent, creating labeled datasets for supervised learning models.
Address class imbalances by ensuring a proportional representation of both legitimate and fraudulent instances in the training data.
As artificial intelligence (AI) systems become increasingly sophisticated in delivering personalized experiences, the ethical implications surrounding user privacy gain prominence. Balancing the benefits of personalization with the imperative to protect user privacy is crucial for fostering trust and maintaining ethical AI practices. This section delves into the nuanced landscape of ethical considerations in AI-driven personalization:
Explainable AI (XAI) refers to the transparency and interpretability of AI algorithms, allowing users to understand the logic behind automated decisions.
Choose AI models with inherent transparency, enabling users to comprehend how decisions are made.
Highlight features that significantly influence personalization decisions, fostering user understanding
Present personalized recommendations with clear and userfriendly explanations, detailing why certain choices are made.
Let’s consider an example of Explainable AI (XAI) in the context of a recommendation system. Suppose you have a personalized movie recommendation system that suggests movies to users based on their viewing history, preferences, and behavior. The goal is to make the recommendations explainable to users. Example: Explainable AI (XAI) in Movie Recommendation
The recommendation system suggests a particular movie to a user.
The system provides an explanation such as "We’re suggesting this movie because it aligns with your preference for science fiction, and it has high ratings from users with similar tastes. Additionally, it takes into account your recent interest in movies with strong female leads."
The recommendation algorithm utilizes interpretable features such as genre preferences, user ratings, and recent viewing history. The system generates a feature importance explanation by highlighting the factors that influenced the recommendation.
A user questions why a specific movie was recommended to them.
The system responds with a personalized explanation tailored to the user’s history, saying, "This movie is recommended because it combines elements from your favorite genres, and it is directed by a filmmaker whose work you’ve enjoyed in the past."
The XAI system creates user-specific explanations by considering the individual’s unique preferences, viewing habits, and historical interactions with the recommendation system.
The system suggests a movie based on the similarity of user preferences to those of other users.
The system explains, "This recommendation is based on users who share similar tastes with you. It considers the preferences of users who enjoyed the same movies you did and suggests this movie as it aligns with their viewing patterns."
The XAI system creates user-specific explanations by considering the individual’s unique preferences, viewing habits, and historical interactions with the recommendation system.
The system suggests a movie based on the similarity of user preferences to those of other users.
The system explains, "This recommendation is based on users who share similar tastes with you. It considers the preferences of users who enjoyed the same movies you did and suggests this movie as it aligns with their viewing patterns." Implementation
A user wants to understand how the recommendation system works and why certain movies are suggested.
The system provides a transparency dashboard where users can explore their viewing history, preferences, and the factors influencing recommendations. It includes visualizations and summaries that break down the recommendation process.
The recommendation system incorporates a user-friendly dashboard that displays relevant information, making the AI’s decision-making process transparent and understandable for the user.
Federated Learning is a privacy-preserving machine learning approach where models are trained on decentralized devices, avoiding the need for raw data transfer.
Train personalization models on user devices rather than a central server, preserving individual user data.
Aggregate model updates rather than raw data, ensuring that sensitive user information stays on local devices.
Implement encryption and anonymization methods to further safeguard user data during the federated learning process.
Privacy-Preserving Techniques involve implementing measures to protect user data while still extracting valuable insights for personalization.
Let’s explore an example of Privacy-Preserving Techniques in the context of a healthcare analytics scenario where sensitive patient data is used to derive insights while ensuring individual privacy. Example: Privacy-Preserving Techniques in Healthcare Analytics
Imagine a healthcare organization aiming to perform analytics on patient data to identify trends, improve treatments, and enhance overall healthcare outcomes. However, privacy is a paramount concern, as the data includes sensitive patient information.
Suppose the organization wants to determine the average recovery time after a certain medical procedure. Differential privacy ensures that the inclusion or exclusion of any individual’s data does not significantly impact the overall result, protecting the privacy of each patient.
For instance, if the organization wants to assess the effectiveness of a specific medication, homomorphic encryption allows them to run analytics on encrypted patient records without revealing the details of each patient’s medical history.
Anonymization techniques are applied to the dataset, removing or generalizing personally identifiable information (PII). Patient names, addresses, and other identifiers are replaced with unique identifiers or generalized categories to protect individual identities.
If the organization needs to analyze the geographical distribution of a particular health condition, anonymization ensures that the location data is generalized (e.g., at the city or regional level) to prevent identification of specific patients.
If multiple healthcare organizations want to collaborate on a research study without sharing patient records, cryptographic techniques enable them to jointly analyze encrypted data and derive insights without compromising individual privacy
Striking the Right Balance involves finding the equilibrium between providing personalized experiences and respecting user privacy.
Implement granular user controls, allowing individuals to specify the level of personalization they are comfortable with.
Make personalization features opt-in rather than opt-out, ensuring users actively consent to the use of their data.
Communicate transparent privacy policies, informing users about how their data is used for personalization and ensuring compliance with data protection regulations.
User Empowerment and Education involve informing and empowering users to make informed decisions about their privacy in the context of personalization.
Provide accessible resources that explain how personalization works and the measures taken to protect user privacy
Offer user-friendly dashboards where individuals can view, manage, and control their personalized preferences and data settings.
Conduct regular privacy audits and communicate the findings to users, reinforcing the commitment to ethical personalization practices.
Ethical considerations in A-driven personalization require a meticulous approach that encompasses explainability, federated learning, privacy-preserving techniques, finding the right balance, and empowering users through education and control. Implementing these ethical principles not only fosters trust but also ensures that personalization efforts align with user expectations and regulatory standards.
In conclusion, the integration of AI technologies in fraud detection and personalization relies on a diverse set of tools and techniques. From machine learning algorithms and predictive modeling to behavioral biometrics and privacy-preserving technologies, organizations have a rich toolbox to harness the power of AI. As advancements continue, the responsible implementation of these technologies, considering ethical considerations and user privacy, will be crucial in realizing the full potential of AI in transforming the landscape of security and user experience [1-8].