Author(s): Janardhana Rao Sunkara*, Sanjay Ramdas Bauskar, Chandrakanth Rao Madhavaram, Eswar Prasad Galla, Hemanth Kumar Gollangi, Mohit Surender Reddy and Kiran Polimetla
These days, the identification of brain tumours has become a standard medical cause. A braintumour is defined as an abnormal mass of tissue in which the cells develop uncontrollably and suddenly; in other words, there is no control over the rate of cell division. To isolate the aberrant tumour location inside the brain, image segmentation is used. The division of brain tissue is a crucial step in the MRI process for determining if outlines of a brain tumour are present. This research used an object segmentation algorithm to separate items in MRI data. In segmenting objects related to brain tumours in MRI images, a linked component labelling approach is used. Analyzing many deep learning pre-trained models for brain tumor detection to be used in various real-world scenarios is the focus of this paper. A goal of this research is to assess the performance of DL in diagnosing brain tumours. The goal of this study is to assess and compare the three advanced DL models: ResNet-18, AlexNet, and VGG-19. This work operate on the Brain Tumor Classification (MRI) dataset which has several tumour classes for classification. The process of automating the detection of brain tumors also goes through several phases characterized as data pre-processing, image standardization, segmentation and extraction of characteristics features. The experimental investigation assessed the models according to accuracy, sensitivity, as well as specificity. It shows that a ResNet-18 model has a higher accuracy of 93. 80% than other models, seconded by VGG-19, which has an accuracy of 91. 27%, and AlexNet with an accuracy of 87. 93%. These results demonstrate that the suggested ResNet-18 model may aid in the enhancement of medical image analysis and performs better in image classification for brain tumour detection.
The health sector is under increasing pressure to use cutting-edge technological solutions to address the growing number of diseases in this age of unparalleled change. Among these diseases, the most deadly one that humanity has encountered so far is the brain tumour. It is quite unlikely that a treatment will be found in time to save a patient's life, even if an illness is diagnosed in its early stages. The tumours may be categorised as either benign ormalignant. On the other hand, malignant tumours include cancerous cells that might possibly be fatal to the patient, but benign tumours do not represent any harm to medical safety. Everyone knows that a brain is a important component of a human body; whatever happens to it will have a direct effect on the patient's expected lifespan [1]. The famous medical tool known as MRI is used for the diagnosis and analysis of several ailments, including brain tumours, neurological disorders, epilepsy, and many more. Usually, this method may be automated to provide rapid and accurate results using a computer- based approach [2]. Concurrently, many applications in computer vision and image processing rely on image segmentation as their primary function. The hash algorithm relies on segmenting the image into subsets defined by predefined metrics in order to facilitate further processing. Commonly, medical professionals may manually use MRI imaging to detect brain disorders [3]. Fatigue and an overabundance of MRI slices are two of the many reasons why the large-scale manual inspection approach might contribute to incorrect interpretation. Also, there is both intra- and inter-reader variability since it is not reproducible [4].
A valuable adjunct to the infamously challenging area of brain tumour surgery, AI plays a substantial role in the identification and diagnosis of brain tumours. New AI subfields, such as DL and ML, have completely altered neuropathology procedures [5]. Image segmentation approaches have been greatly enhanced by the rapid advancements in AI, especially DL. While it comes to image segmentation, the results of DL-based methods are rather higher than to do the same conventional multiple learning and computational vision methods as for speed and accuracy [6]. Specifically, the use of DL for medical image segmentation enables accurate estimation of tumour size and quantitative evaluation of treatment efficacy. These approaches are complex and involve several procedures such as feature extraction, data preprocessing methods, feature reduction, feature selection methods, and classification [7]. Apart from DL, there is the possibility of developing other segmentation techniques that are more reliable and precise than the current methodologies [8]. Image segmentation can hence be regarded as a classical methodological paradigm of the early stage of the development of the field of ML, which has only recently risen to the mainstream of the DL domain [9]. On the other hand, CNNs and other DL technologies changed the face of image segmentation process by enabling automated feature extraction and obtaining hierarchical representation [10]. CNNs that are deep learning algorithms have been proven to produce excellent results in image related tasks that include object recognition and segmentation.
This study aims to address the challenge of brain cancer classification by using DL methods on the brain tumour Classification (MRI) dataset. This research will use CNN architectures to classify MRI images into particular categories, such as glioma, meningioma, and pituitary tumours.This study aims to assess an efficacy of DL models in precisely differentiating various tumour types, as well as investigating the possible advantages and constraints of using these methods in a clinical environment. The resrach contribution of this work as:
A following paper are organizaed as: Section I and II provide the introduction of topic with research contribution also existing literature review on this topic with comparative summry. Section III provide the methodlogy of this work with proposed flowchart and each methods. Section IV discussed a results and discussion of the DL models with comparative analysis. Section V provide the conclusion of this work with future work and limitaions.
Various techniques for medical image classification based on DL, such as transfer learning, CNNs, ML, and hybrid approaches, are covered in this section. Research into tumour segmentation is an active field. A recent validation study confirmed the usefulness of DL for analysing medical images.
In, use a suite of data pre-processing methods to improve the overall dataset and highlight specific features within the original data [11]. The enhanced DeepLab v3+ segmentation DCNN was another DL model that improved prediction and training performance on the thyroid nodule dataset. Dice similarity coefficient of 94.08% and accuracy of 97.91% are measured in the findings, demonstrating the advanced nature of our technology.
To, provide a deep levelset technique to enhance an accuracy of object segmentation and increase object boundary details [12]. We use enriched previous information into CNN's inputs to provide a level set evolution result with a more precise shape. We assess the suggested approach using two sets of medical imaging data: retinal fundus pictures and prostate magnetic resonance images. The experimental findings provide advance performance from a proposed method.
In, offers a neural network architecture that may be used to segment medical imaging data. Our selection is to conduct experiments and use different CNNs [13]. We decided to use this study on the segmentation of cerebral images that include brain tumours. Selecting the optimal architecture and parameterisation to be applied to an MRI brain tumour job while managing a small database is the primary goal. Our customised CNN architecture performs well in segmentation and learning evaluation tests.
Within this framework, create two models for anatomically directed segmentation: AG-UNet and AG-FCN [14]. Anatomically gated U-Net and fully convolutional network are the acronyms for their respective names. Results in ROI segmentation of brain MR images using the proposed AG-FCN and AG-UNet algorithms outperform other state-of-the-art methods when evaluated on the ADNI and LONI-LPBA40 datasets.
In, A DL model is used to categorise the three most prevalent forms of brain tumours: pituitary, glioma, and meningioma. With a time-efficient categorisation approach, this research aims to reduce the workload for clinicians. Ninety percent accuracy is possible using the developed method [15].
In, created a cutting-edge deep-learning segmentation model called MultiResUnet [16]. This model has 2 section: an encoder for capturing features and a decoder for accurate localisation. According to experiments conducted using LOOCV and ground- truth image comparisons employing Tanimoto similarity, MultiResUnet achieves an average accuracy of 91.47%, which is almost 2% better than the autoencoder. An improvement over our earlier model, MultiResUnet provides a method for segmenting breast IR images.
In, For the automatic identification of tumours in brain scans, a CNN-based technique is suggested [17]. The approach is evaluated using MR brain images provided from the Harvard Medical School database. The study makes use of three pre-trained models: Inception, ResNet, and VGG16. It is possible to reach 100% accuracy on the tested database.
Inspired by the recent achievements in using DL techniques for medical image processing, first provide an algorithmic architecture for cross-modality fusion in supervised multimodal image analysis at a classifier, feature learning, and decision-making stages [18]. When contrasted with networkstrained on single-modal images, a multimodal network performs far better. Rather of fusing pictures at the network output (i.e., voting), it is usually preferable to fuse images inside a network (i.e., at convolutional or fully connected layers) while doing tumour segmentation. In order to help with the development and implementation of multimodal image analysis, this study presents empirical recommendations.
Table 1 shows the performance results of the related works.
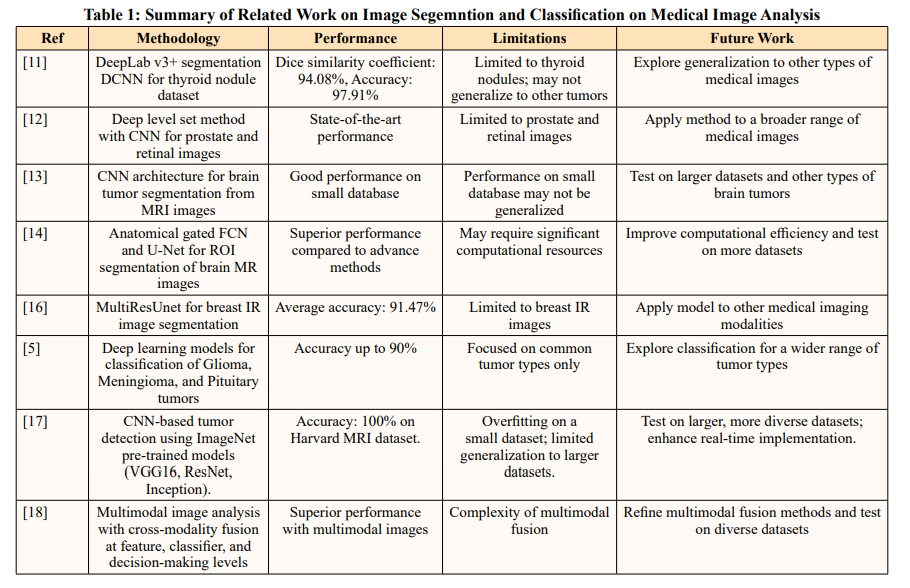
The process for classifying brain tumour pictures starts by gathering the Brain Tumour Classification (MRI) dataset, including 3,264 images representing four different kinds of tumours. In the data preprocessing phase, all photos undergo greyscale conversion and are then enlarged to dimensions of 224x224 pixels. Greyscale photographs, consisting only of various shades of grey, depict the light intensity shown at each individual pixel. An use of filtering techniques serves to enhance the quality of images, including sharpening filters to amplify fuzzy features and smoothing filters to diminish noise. Edging is a process used to identify sharpness in captured photographs. Following that, image augmentation is used to improve a predictive capacity of a model. Following a preprocessing stage, the braintumour areas are divided into segments, and contrast modifications are used to enhance the segmentation. Extraction of features is performed to obtain significant characteristics from the photographs. Training and testing runs are divided using an 80:20 ratio of the dataset. The employment of three DL models—ResNet-18, VGG-19, and AlexNet—led to the calculation of performance indicators like accuracy, sensitivity, specificity, and precision. By evaluating and contrasting the models using these measures, the top performing model was ultimately identified. A potential approach for categorising brain tumours is shown in the flowchart in Figure 1.
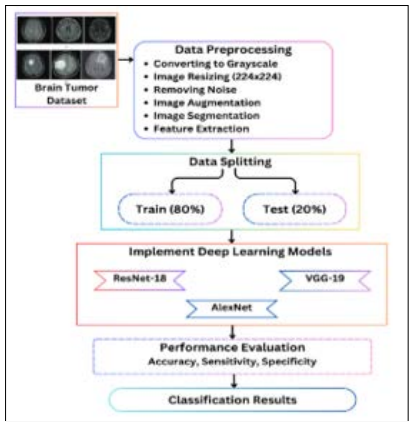
Figure 1: Proposed System Flowchart for Brain Tumor Identification
An extensive open-source collection developed to aid in the interpretation of medical images—more especially, in the classification of brain tumors—the "Brain Tumour Classification (MRI)" dataset is available on Kaggle. With a total of 3,264 T1-weighted, contrast-enhanced MRI images, the collection is organised into two main files: one with 28,70 images for training and another with 394 images for testing. The photos depict four well-defined categories: pituitary gland tumor (901images), glioma 826 images), meningioma (937images), and healthy brain (500images). Every picture in the collection is specifically labelled to indicate its category, making the dataset appropriate for the training of DL models in a classification of braintumors. Due to the fact that using machine learning methods it is possible to obtain a development of diagnostic systems capable of accurately diagnosing brain abnormalities, this resource is useful. It also has the utility of enabling medical research as well as improving the effectiveness of algorithm approaches in medicine. Sample images from a dataset to classify brain tumour are presented in Figure 2 below.
Figure 2: Sample Images of Brain Tumor Classification (MRI) Dataset
Data preparation remains the vital steps in each and every machine learning procedure. During this data preprocessing phase of this work all MRI pictures are first converted to greyscale. In this format, each pixel is representing the intensity of the light making easier the analysis of an images. After maintain consistency and compatibility with deep learning models, all these photos are then resized to 224 x 224 photos. There are numerous filtering procedures that are utilized to improve a quality of image and sharpening filters that are used on a fuzzy features of images, whereas, the usage of smoothing filters reduces the noise. Shading is also done in order to define the sharpness and boundaries in the photographs. To expand the dataset and enhance the model's prediction capabilities, it also employs image augmentation methods including flipping, rotating, and zooming. After preprocessing, the tumour fields are partitioned into segments and contrast adjustments for the enhancement of picture are applied.
During the data preprocessing phase, segmentation is critical to identifying brain tumors in MRI scans with high levels of accuracy. This process involves segmentation of images whereby the tumor areas are separated from the normal tissues by partitioning, thresholding, region growing and edge detection. Subsequently, enhancements are made upon the contrast in order to give more prominence to the tumor regions. These segmentation steps guarantee that the DL models’ analysis concentrates on the tumor features in question, enhancing the classification algorithms’ reliability.
Maximizing the use of the given dataset and finding the hidden pattern in the data is crucial. The present work applied tools of data visualization that allowed to represent hidden patterns or trends in the data properly.
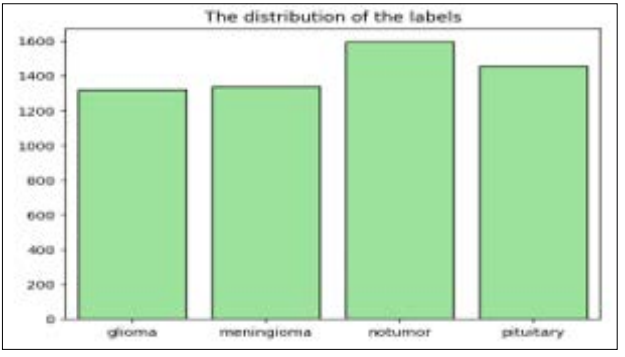
Figure 3: Count Plot for Distribution of Labels
Using count plot, the proportions of the labels in the brain tumor classification dataset are depicted in figure 3. The x-axis of plot signifies tumor classes such as glioma, meningioma, no tumor, and pituitary The y-axis in plot represents count of every tumor class starting from 0 up to 1600. The spi of the bar graph that shows information regarding the count of glioma tumor class is noted to be approximately 1250 and that of the meningioma tumor class is approximately 1300 while that of no tumor class and the pituitary tumor is noted to be approximately 1600.
This section offers a complete analysis of three DL models in order to better understand their potential for identifying brain tumours.
Figure 4 displays the architecture of a CNN called VGG19, which consists of 19 layers. Developed by a separate group at Oxford University called the Visual Geometry Group, VGG builds upon and improves upon the concepts of its forerunners. It improves accuracy by building on previous systems' concepts and principles and by adding deep convolutional neural layers [19].
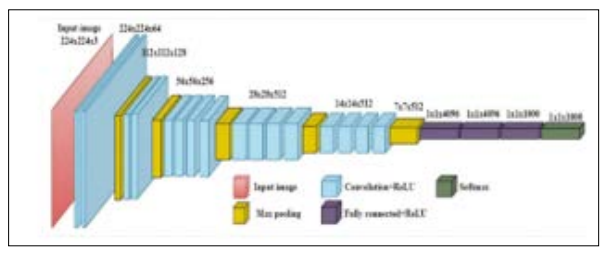
Figure 4: General Architeture of VGG-19 Model
Images may be recognised using VGG, an advanced CNN. The network's usage of an RGB image with a fixed size of 224 × 224 as input indicates that the matrix was constructed, and the characteristics of the data set were (224,224,3). To begin with, no preprocessing was carried out beyond averaging the RGB values of all the pixels in the training set. The entire image might be covered by their 3 × 3 pixel kernels with a stride size of 1 pixel. In order to maintain the spatial resolution of the image, spatial padding was used. While previous models made use of tanh or sigmoid functions, this one employed max pooling 2 x 2 pixel windows with Stride 2. ReLu
AlexNet is a large-scale network structure with 650,000 neurones and 60 million parameters. It far outperformed conventional techniques, highlighted the possibilities of DL, and set the stage for the later creation of DCNNs. An important advancement in image classification tasks was made by AlexNet [20]. The network's design was an eight-layer DCNN. There are three Fully Connected (FC) layers and five convolutional layers in the eight layers. To guarantee neurone activity, the softmax layer's function is to regulate an output in a range of (0,1). A softmax layer's normalisation procedure was represented in Eq. 1.
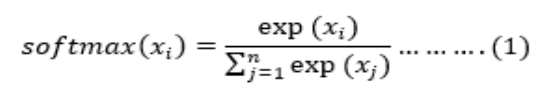
where n is a dimension of the input tensor and xxii is also its ii th predicted value. ReLU were one of AlexNet's ground-breaking inventions; by employing ReLU as activation functions, training convergence was significantly accelerated. Additionally, AlexNet made good use of dropout and data augmentation methods to assist avoid overfitting. In addition to having a significant impact on many later designs and cutting-edge CNN research, AlexNet was also a major component of earlier CNN generations.
Figure 5 displays a squeeze-and-excitation Basic Block (SEBB) module, which is a foundation of a DL-based ResNet model. There are a total of twenty-two layers in this design, including a fully connectedlayer, a global average poolinglayer, CV1, SEBB, CV2_x, CV3_x, CV4_x, and CV5_x. The CV1 is made up of the following layers: Convolution, Batch Normalisation, ReLU activation function, and Maximum Pooling [19]. The following parameters are currently used by the Convolution layer: stride-2, Padding-3, and a 7x7 kernel. Following this, stride-2, padding1, and a 3x3 kernel size are all part of a maximum poolinglayer's configuration. Use of a maximum poolinglayer results in a drastic reduction in both dimensions and parameters. This approach must conserve substantial feature information while simultaneously increasing the receptive fields. ResNet-18, which includes both a SE module and a residual basic block, is linked to the SEBB module. The last is the rest of the ResNet-18 network, which includes two Convolution layers, named Convolution layers 3 and The basic building block of a SEBB module is a combination of the SE module and the residual block. As stated earlier, the stride-1 and 3x3 kernels represent two of the Convolution layers within the SEBB module.
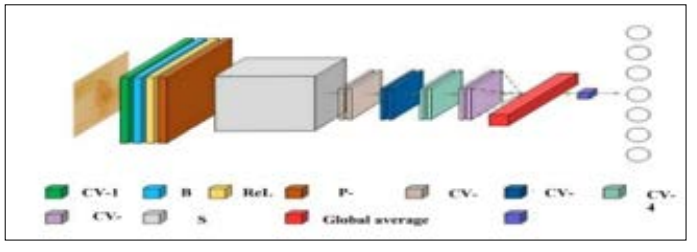
Figure 5: Architecture of ResnNet-18 Model
The model architecture comprises of two convolutional layers, namely CV-1 and CV-2, which are followed by ReLU activation and Batch Normalisation. The squeezing and the excitation procedures are part of the SE module. Here, a global average pooling layer is to convert the feature map to vector. The activation process consists of two Fully Connected layers which include ReLU and another process of Sigmoid. Fully Connected layers are defined by their 1x1xC inputs and 1x1xCx1/r outputs. The purpose of the scaling parameter r is to reduce the amount of channels used for reduction calculation to a minimum. If you take this following Fully Connected layer, its input is 1x1xC and its output is 1/r. This approach scales the 1x1xC vector and then initialises the feature map after acquiring the 1x1xC vector. When the SE module's channel output weights are multiplied by a 2D matrix, the resulting actual feature map size is WxHxC. The relevant feature map of the channel is executed using this approach to get a final solution. There is a global average pooling layer that connects CV-3 to CV-6. This layer fits an output into a 1x1 kernel size and is also called the Adaptive AvgPool function. Finally, the ResNet classification result is 7. This is provided by the fully connected layer. It is also possible to learn and classify the related data using other sorts of datasets.
The ResNet-18 model, incorporating a Squeeze-and-Excitation Basic Block (SEBB), is trained with hyperparameter tuning to optimize its performance. The Adam optimiser is a powerful tool for efficiently reaching the best solution because of its adjustable learning rate capabilities. To find out how well the model's predictions for class probabilities match up with the actual labels, we use the cross-entropy loss function as our classification accuracy metric. In terms of memory efficiency and speed of model convergence, to perform the training procedure it is using the batch size equals to 64. To ensure that the model gets adequate learning without over fitting it is trained for 10 epochs.
It is necessary to employ loss and accuracy metrics to assess how well the DL models performed with the test/validation and train/ test sets. A training loss represent the ability of elements of a training dataset to fit a model. The validation set is very essential in the process of dataset division where most of the data is used for training purposes while a small portion is set aside particularly for the validation of the model. There are many metrics, but one of them must do with measurement of the DL model’s validation loss. The folloqing performance model evaluation measures are discussed below:
Confusion Matrix: The most suitable way to decide on the categorisation system may involve an employ of a confusion matrix. In a confusion matrix, several model parameters are defined which includes accuracy, True Positive (TP), True Negative (TN), False Positive (FP) and False Negative (FN). A following performance measures as:

Where,
Tumour instances appropriately detected and labelled by the model are represented by TP, whereas non-tumor cases that were mistakenly classified as tumours are represented by FP. Unrecognised tumours (FN) are ones that the diagnostic procedure overlooked. True negatives (TN) are those that were precisely as predicted.
Using a confusion matrix and a loss/accuracy plot, this section analyses the ResNet-18 model's performance in classifying photos of brain tumours. Study examines VGG-19, AlexNet, and ResNet-18 models' specificity, sensitivity, and accuracy scores to evaluate their effectiveness in a realm of deep learning.
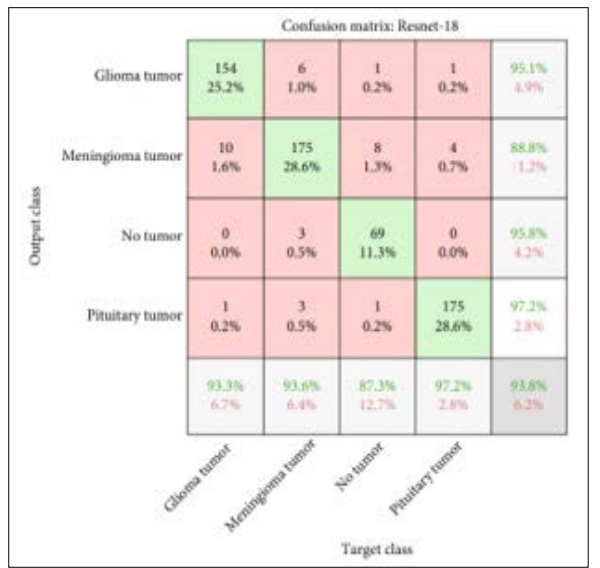
Figure 6: Confusion Matrix of ResNet-18 for Brain Tumor Detection
The effectiveness of the classifier in classifying brain tumour images is shown by a confusion matrix of a ResNet-18 model, which was evaluated employing a testing data, as shown in Figure.
The confusion matrix's x-axis displays a target class, and a y-axis predicts an output class. According to the presented data in the confusion matrix, the ResNet-18 model accurately predicts 154 or 22.2% images of glioma tumor, 175 or 28.6% images of meningioma tumor, 69 or 11.3% images of no tumor and 175 or 28.6% images of pituitary tumor.
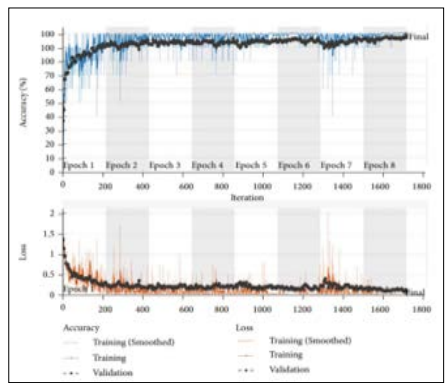
Figure 7: Training and Validation Accuracy and Loss Graph for ResNet-18 Model
Figure 7 illustrates the ResNet-18 model's accuracy and loss graphs during training and validation, which have been performed using a brain tumour classification dataset to illustrate the model's predictive capabilities for brain tumours. The graph’s x-axis represents an epochs ranging from 1-8, while a y-axis represents an accuracy and loss for every epoch. In the figure, the training accuracy is increasing slowly, approaching 100%, with minor fluctuations in validation accuracy, as shown in the top (accuracy) graph. On the other hand, the loss curves for both training and validation are lowering steadily, as displayed in a bottom (loss) graph.
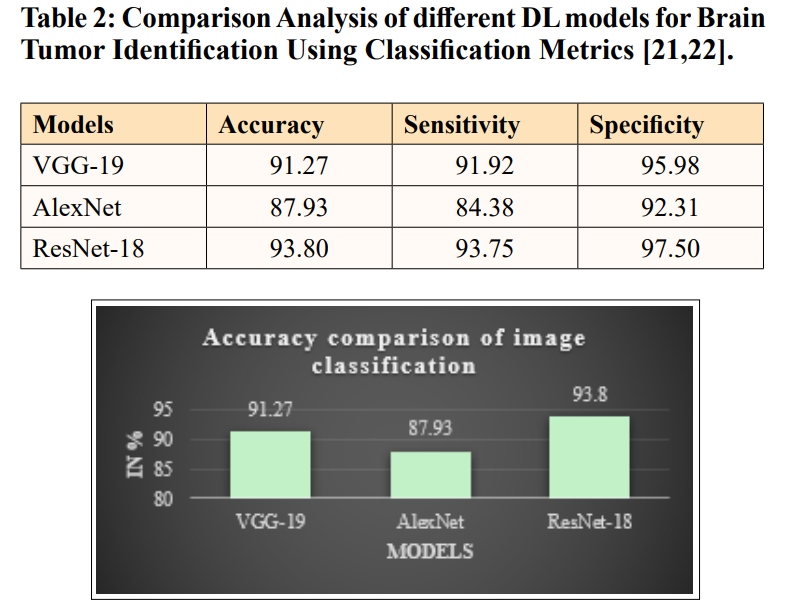
Figure 8: Comparison of Accuracy Measures for Different DL Models for Brain Tumor Detection
The above-mentioned Figure 8 and Table II provide a comparison of accuracy measures for different models to determine an optimal model for brain tumour image classification. The graph’s x-axis indicates deep learning models namely VGG-19, AlexNet, and ResNet-18, while the y-axis indicates the accuracy scores of each model as a percentage. The graph clearly depicts that the ResNet-18 classifier has the highest accuracy of 93.8, VGG-19 has an accuracy of 91.27%, and the AlexNet has an accuracy of 87.93% in the testing phase. Overall, the comparison demonstrates that the ResNet-18 model outperforms others in classifying brain tumor.
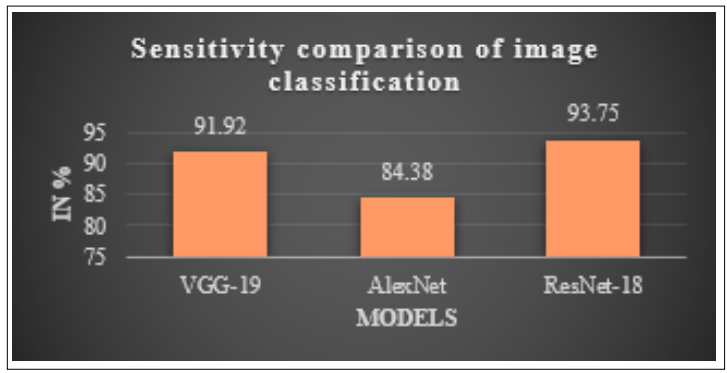
Figure 9: Comparison of Sensitivity Measures for Different DL Models for Brain Tumor Detection
Figure 9 and Table 2 provide a comparison of sensitivity measures for many models with the goal of determining which model is best suited for categorising images of brain tumours. The x-axis of the graph signifies deep learning models, namely VGG-19, AlexNet, and ResNet-18, while a y-axis shows a sensitivity scores of each model expressed as a percentage. The data graphic clearly illustrates that the ResNet-18 classifier achieves the maximum sensitivity of 93.75%, followed by VGG-19 with a sensitivity of 91.92%, and AlexNet with a sensitivity of 84.38% throughout the testing phase. When compared to other models, the ResNet-18 model routinely outperforms them when it comes to brain tumour classification.
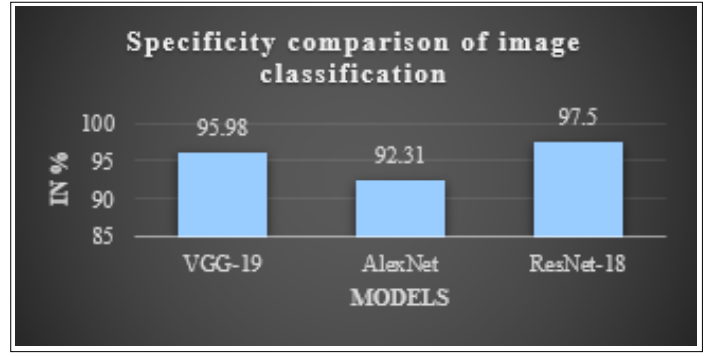
Figure 10: Comparison of Specificity Measures for Different DL Models for Brain Tumor Detection
An optimal model for brain tumour image classification may be found by comparing the specificity metrics of many models, as shown in Figure 10 and Table II. VGG-19, AlexNet, and ResNet-18 are the DL models represented on the x-axis of the graph. The specificity scores of each model are represented as a percentage on the y-axis. The graph plainly illustrates that the ResNet-18 classifier has the highest specificity of 97.5%, followed by VGG- 19 with 95.98% and AlexNet with 92.31% in the testing phase. The ResNet-18 model is often shown to be superior to other models when it comes to classifying brain tumours, according to the study.
This research aims to identify how DL models with MRI can be employed to detect brain tumours at their early stage. Comparisons were made between DL models used in a classification of brain tumours and demonstrated the efficiency of intricate architecture in the medical image analysis. Therefore, three of these DL models: Alexnet, Resnet-18 and VGG-19 were trained and tested on their ability to detect brain tumour by MR images. Thus, among all of them, ResNet-18 provides the highest percentage of accuracy which is equal to 93. 80%. The next best performer was VGG- 19 at 91. 27% closely followed by AlexNet at 87. 93% on the same metric. From the obtained results, it could be deduced that ResNet-18 still performs well in the classification of brain tumours no matter the complexities such as varied kinds of tumour or image quality. The general advantage of an automated technique is that it cuts down the dependence on human interpretation and increases diagnostic efficiency by a very wide margin. Apparently, the improvement of structural designs like Transformer-based models or the utilization of multimodal data to enhance the classifying precision might be the concern of the following study. Integrating the model with real cases of clinical data and applying the dataset to comprise other types of tumors may potentially enhance its applicability and adaptability. New possibilities for developing diagnostic tools that can quickly and effectively diagnose tumours in clinical practice can be the subject of future research. Developments on these aspects and employing deeper architectures to enhance the performance of the segmentation output will be the aspect of further studies.